Penyusunan Html Menggunakan Xquery – Format html yang disusun dengan sangat baik menjadi salah satu kunci utama kesuksesan sebuah situs html. Tentu saja dengan adanya situs html yang terstruktur dengan rapi memungkinkan para penggunanya dapat menyesuaikan dengan lebih mudah.
Fleksibilitas dari prosesor xquery yang digunakan memungkinkan para pembangun website memiliki kesempatan yang lebih luas untuk membangun sebuah situs website yang lebih mudah dipahami oleh penggunanya. Xquery memberikan fasilitas kepada pembangun situs untuk membuat situs yang lebih informatif. Penggunaan bahasa program yang lebih terstruktur memungkinkan para penggunanya bisa lebih mudah dalam melakukan penyusunan html dari sumber data yang lebih akurat. Bahasa program yang lebih sederhana dan tidak terlalu menyulitkan memudahkan penggunanya untuk menyusun website dengan format yang lebih mudah.
Prosesor xquery memiliki bahasa perintah program yang sama sekali tidak rumit. Kesederhanaan dari bahasa perintah diwujudkan dalam bentuk infrastruktur program yang lebih rapi. Infrastruktur program dan perintah program yang digunakan berbentuk seperti infrastruktur berupa pohon yang lebih rapi. Penggunaan bentuk infrastruktur seperti pohon memungkinkan prosesor ini untuk bekerja dengan lebih maksimal. Infrastruktur seperti pohon merupakan infrastruktur program yang sangat sederhana. Di dalam infrastruktur tersebut terdapat banyak sekali simpul yang mudah dioperasikan. Seperti atribut, dokumen, teks, kolom komentar, kolom untuk nama dan beberapa atribut pendukung lainnya yang mendukung terciptanya sebuah website yang informatif.
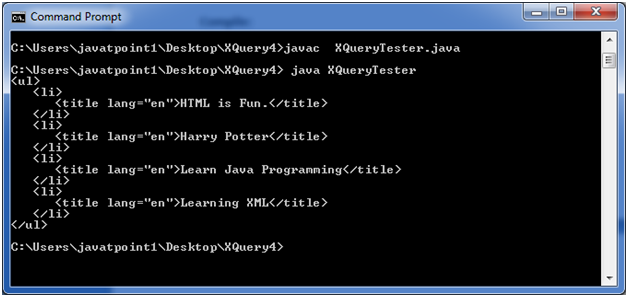
Prosesor xquery bisa dikatakan sebagai salah satu prosesor yang cukup tua. Mengingat bahwa prosesor ini sudah mulai digunakan sejak awal tahun 90 an. Meskipun merupakan prosesor yang sudah cukup tua, namun untuk membangun html hingga kini masih bisa dimanfaatkan sebagai salah satu media untuk membangun situs yang akurat dan juga informatif. Akurasi dan juga semua informasi yang bersumber dari sumber data yang jelas bisa dimasukkan secara sempurna. Bahasa pemrogramannya yang sangat sederhana meskipun sudah cukup tua akan tetapi masih sesuai digunakan sampai saat ini untuk membangun sebuah website yang informatif dengan gaya yang lebih sederhana. Sebagai contohnya, Anda bisa melihat langsung ke website yang menggunakan bahasa pemrograman Prosesor xquery.
Meskipun bahasa program dan atribut-atributnya tergolong sederhana, namun pada kenyataannya komponen atribut tersebut masih layak dijadikan salah satu alat untuk membangun sebuah website yang informatif. Strukturnya yang lebih sederhana namun lebih rapi memungkinkan siapa saja yang menggunakannya bisa membuat website dengan lebih mudah dan lebih sederhana. Itulah sebabnya mengapa prosesor xquery masih dianggap sesuai untuk membangun situs html yang sederhana dengan banyak informasi dan konten yang bisa dimasukkan di dalam website. Kesesuaian inilah yang membuat xquery masih dipilih sebagai prosesor yang cukup ampuh untuk membuat situs html dengan konten yang cukup padat. Proses penyusunannya yang lebih mudah dan relatif lebih cepat memastikan bahwa xquery menjadi komponen bahasa program html yang cocok untuk digunakan sebagai pembuat html yang sesuai sepanjang masa.

Edukasi tentang pemeliharaan dan perawatan komputer
Edukasi tentang pemeliharaan dan perawatan komputer – Apakah Anda memerlukan perawatan perbaikan komputer? Tentu saja ya! Kadang-kadang, sebagai contoh, remah-remah, debu, dan partikel lain yang jatuh di antara komputer dan bagian-bagiannya dapat menumpuk seiring waktu dan membahayakan PC Anda.
Edukasi tentang pemeliharaan dan perawatan komputer
zorba-xquery – Itu sebabnya kami mengendurkan tombol dengan menyemprotkan udara bertekanan ke keyboard. Dan kemudian dihapus dengan penyedot debu bertekanan rendah.
Baca Juga : Panduan Lengkap Tentang XQuery untuk Pemula, Pembelajar Menengah & Lanjutan
Bahan pembersih plastik yang diaplikasikan pada permukaan kunci dengan kain digunakan untuk menghilangkan akumulasi minyak. Serta kotoran dari kontak berulang dengan ujung jari pengguna.Jika ini tidak cukup untuk keyboard yang sangat kotor, tombol akan dihapus secara fisik. Memungkinkan pembersihan individu yang lebih terfokus, atau untuk akses yang lebih baik ke area di bawahnya.
Permukaan atas mouse dilap dengan pembersih plastik untuk menghilangkan kotoran yang menumpuk akibat kontak dengan tangan. Dan seperti pada keyboard, permukaan bawah juga dibersihkan untuk memastikan dapat meluncur dengan bebas.
Dan jika itu adalah mouse mekanis , trackball akan dikeluarkan. Tidak hanya untuk membersihkan bola itu sendiri tetapi juga untuk mengikis kotoran dari pelari yang merasakan pergerakan bola. Dan bisa menjadi gelisah atau macet jika terhalang oleh kotoran. Akhirnya, bagian permukaan dibersihkan dengan disinfektan.
Apa itu Pemeliharaan Perbaikan Komputer?
Pada dasarnya, pemeliharaan perbaikan komputer adalah proses mengidentifikasi, mengatasi masalah, dan menyelesaikan masalah komputasi. Selain itu, ini juga mencakup kegiatan lain untuk mengelola masalah pada perangkat keras komputer, perangkat lunak, atau bahkan ethernet yang rusak .Penting untuk disadari, solusi layanan pemeliharaan perbaikan pada komputer merupakan suatu bidang yang banyak meliputi prosedur, alat dan tekniknya . Digunakan, khususnya, untuk pemeliharaan perbaikan komputer yang terkait dengan masalah komputasi umum.
Dengan kata lain, pemeliharaan perbaikan komputer juga dikenal sebagai perbaikan PC. Dan, oleh karena itu, ini adalah praktik menjaga komputer dalam kondisi kerja yang baik dari perbaikan.Semua orang yang memiliki komputer tahu saat panik ketika hard drive mogok. Dan bagi para pebisnis, hal itu biasanya terjadi ketika mereka sedang menghadapi tenggat waktu. Misalnya, komputer yang berisi akumulasi debu dan kotoran mungkin tidak berfungsi dengan baik.Sederhananya, karena debu dan kotoran akan menumpuk akibat pendinginan udara. Dan filter apa pun yang digunakan untuk mengurangi ini memerlukan layanan dan/atau perubahan reguler.
Tip umum untuk perawatan perbaikan komputer
Pada akhirnya, setelah pemecahan masalah, bagian perangkat keras ditambahkan atau diganti jika kesalahan terdeteksi.Ini biasanya memerlukan peralatan dan aksesori khusus untuk membongkar dan memasang kembali komputer. pada perbaikan komputer ada masalah yang sering terjadi karena pembaruan sistem ataupun konfigurasinya .
Kesalahan aplikasi yang diinstal, virus, dan masalah perangkat lunak lainnya juga diidentifikasi. Demikian pula, perbaikan komputer untuk masalah jaringan/Internet memungkinkan komputer untuk sepenuhnya memanfaatkan layanan jaringan dan yang tersedia. Padahal, A+ adalah sertifikasi vendor-netral untuk memperbaiki dan memelihara komputer.Di bawah ini Anda akan melihat tip umum untuk pemeliharaan perbaikan komputer yang berhasil. Dan pertama, Anda harus mulai dengan cara memperbaiki kesalahan sederhana yang mungkin dimiliki komputer Anda;
1. Blue screen
Kesalahan umum pertama yang biasanya dimiliki komputer adalah kesalahan layar biru. Dan untuk hal ini, orang harus:
Pahami Blue screen
Waktu yang lebih sulit akan datang ketika PC Anda menolak memuat data apa pun. Data ini akan mendapatkan akses ke PC Anda melalui celah di sistem operasi atau di perangkat lunak aplikasi.Untuk memperbaiki PC Anda dan menghilangkan program-program ini, Anda harus memindai komputer Anda dengan program anti-virus yang tepat.
Periksa kesalahan registri
Registry Windows menyimpan informasi mengenai pengaturan perangkat keras dan perangkat lunak pada komputer Anda. Jika program jahat merusak Registry, itu dapat menyebabkan kesalahan layar biru.Masalah ini dapat diperbaiki secara manual, dengan mengedit Registry secara langsung, atau dengan perangkat lunak pihak ketiga. Terutama, yang dapat memeriksa dan memperbaiki Registry yang rusak. Selalu buat cadangan Registry sebelum mencoba mengeditnya.
Pembekuan Komputer
Komputer Anda mungkin membeku karena masalah perangkat lunak atau perangkat keras. Dengan demikian, Anda harus mencari tahu alasan yang tepat untuk mengetahui cara terbaik untuk memperbaiki kesalahan. Anda harus memperhatikan apakah masalah dimulai atau tidak saat Anda menyambungkan periferal perangkat keras apa pun, seperti pemindai atau printer.
Setelah itu, mungkin karena konflik driver. Jika yang terakhir terjadi setelah Anda merakit hard drive baru, mungkin karena daya yang tidak tepat atau suhu yang terlalu tinggi. Jadi, Anda harus mengikuti langkah-langkah yang saya sebutkan di sini untuk menangani masalah ini:
Setel ulang komputer untuk sementara waktu
Jika Anda meninggalkan komputer sepanjang waktu, Anda dapat memperbaiki kesalahan dengan mencabutnya, lalu menunggu minimal 30 detik, dan memasangnya kembali.Hanya dengan mematikan daya komputer ke motherboard, perangkat keras di komputer Anda akan dapat mengatur ulang dan menghapus memori.
Tentukan suhu komputer Anda
Penting bagi Anda untuk melihat ke dalam untuk suhu PC. Anda harus memperhatikan diri Anda sendiri bahwa setiap kali Anda perlu membuka lemari komputer Anda, Anda harus mematikan PC dan mencabutnya. Jika rambut Anda panjang, Anda harus mengikatnya ke belakang.Kemudian lagi, Anda harus melepas perhiasan yang mungkin menghalangi. Padahal, Anda juga harus menghindari mengenakan pakaian yang dapat menghasilkan banyak statis yang dapat menyebabkan intermiten dan merusak perangkat keras, sehingga lebih sulit untuk mengatasi kesalahan.
Periksa kabinet komputer & sasis logam
Jika benar-benar panas, pasti akan ada masalah termal. Anda harus memeriksa kipas depan dan belakang dengan hati-hati dan meniup debunya. Anda juga harus membersihkan kipas secara teratur. Sebelum Anda membersihkan komputer, Anda harus ingat untuk mematikannya.Faktanya, jika Anda memiliki lebih dari hard drive di komputer, Anda harus menghindari menginstalnya.
Terutama tepat setelah saling bergesekan di dalam sasis karena hal ini dapat membuat mereka lebih mudah mengalami kegagalan pada panas.Poin penting lainnya, sebelum menutup kasing, Anda harus ingat untuk memeriksa semua kabel untuk memastikan semuanya masih terpasang. Jika Anda perlu mengatur ulang stik memori atau kartu video, Anda tidak boleh memberikan tekanan berat pada motherboard karena ini akan menjadi rusak.
Pesanan beton / periksa disk
Akses Pemulihan Sistem Saat Mulai> Program> Aksesori> Alat Sistem> SistemHard disk Anda adalah gudang informasi, jadi ketika digunakan untuk waktu yang lama mungkin akan berantakan dan tidak merata; ini memperlambat kinerja komputer Anda. Oleh karena itu, gunakan utilitas Windows Anda CHKDSK untuk memindai dan menghapus bad sector secara teratur.Ini adalah cara pencegahan terbaik untuk menjaga kesehatan komputer.
Periksa drive disk perangkat Anda
Sering kali saat melakukan Pembaruan Windows, sistem Anda mungkin mengunduh dan menginstal driver yang salah, yang dapat menyebabkan komputer membeku. Anda dapat memeriksa status driver dari Device Manager. Cabut perangkat USB Anda, jika terhubung.Nyalakan komputer Anda dan lihat apakah itu berfungsi. Jika ya, bagus; jika tidak, Anda dapat memulihkan komputer Anda ke konfigurasi sebelumnya. Pemulihan Sistem akan mengembalikan sistem Anda ke set driver sebelumnya.

Panduan Lengkap Tentang XQuery untuk Pemula, Pembelajar Menengah & Lanjutan
Panduan Lengkap Tentang XQuery untuk Pemula, Pembelajar Menengah & Lanjutan – Spesifikasi untuk bahasa kueri yang memungkinkan pengguna atau pemrogram untuk mengekstrak informasi dari file Extensible Markup Language (XML) atau kumpulan data apa pun yang dapat berupa XML adalah XQuery. Sintaksnya dimaksudkan agar mudah digunakan serta dipahami. Namun, ada banyak lagi yang perlu diketahui tentang XQuery.
Panduan Lengkap Tentang XQuery untuk Pemula, Pembelajar Menengah & Lanjutan
Baca Juga : Pelajari XQuery dalam 10 Menit
zorba-xquery – Jadi, mari melangkah lebih jauh menuju studi terperinci tentang XQuery. Padahal, sebelum mempelajari XQuery, kita harus memiliki pengetahuan dasar tentang XML. Oleh karena itu, mari kita mulai dengan pengenalan XML secara singkat.
XML
XML adalah kependekan dari Extensible Markup Language. Ini tidak lain adalah bahasa markup berbasis teks yang berasal dari Standard Generalized Markup Language (SGML).
Selain itu, alih-alih hanya menentukan cara menampilkannya seperti tag HTML, tag XML mengidentifikasi data dan juga digunakan untuk menyimpan dan mengatur data, yang digunakan untuk menampilkan data. XML memperkenalkan kemungkinan-kemungkinan baru dengan mengadopsi banyak fitur HTML yang sukses namun tetap tidak akan menggantikan HTML di masa depan.
Sekarang, kita bisa belajar tentang XQuery. Jadi mari kita mulai dengan panduan pengantar XQuery.
Apa itu XQuery?
Bahasa fungsional yang kami gunakan untuk mengambil informasi yang disimpan dalam format XML adalah apa yang kami sebut XQuery. Kita dapat menggunakannya pada dokumen XML, database relasional yang berisi data dalam format XML, atau Database XML. Sejak 8 April 2014, XQuery 3.0 adalah rekomendasi W3C.
Dengan kata lain, bahasa kueri fungsional yang kami gunakan untuk mengambil informasi yang disimpan dalam format XML adalah XQuery. Kita dapat mengatakan, apa itu SQL untuk database, sama halnya dengan XQuery untuk XML. XQuery terutama dirancang untuk meminta data XML.
XQuery dibangun di atas ekspresi XPath. Selain itu, ini adalah rekomendasi W3C yang didukung oleh semua database utama.
Nah, definisi XQuery pada dokumentasi resminya adalah sebagai berikut:
“XQuery adalah bahasa standar untuk menggabungkan dokumen, database, halaman Web, dan hampir semua hal lainnya. Ini diterapkan secara luas. Sangat kuat dan mudah dipelajari. XQuery menggantikan bahasa middleware berpemilik dan bahasa pengembangan Aplikasi Web. XQuery menggantikan Java yang kompleks atau program C++ dengan beberapa baris kode. XQuery lebih sederhana untuk digunakan dan lebih mudah dirawat daripada banyak alternatif lain.”
Terminologi XQuery
Node
Ada berbagai jenis node di XQuery, seperti atribut, elemen, teks, namespace, instruksi pemrosesan, node dokumen (root), dan komentar. Selain itu, dokumen XML diperlakukan sebagai pohon node. Dan, akar pohon dikenal sebagai simpul dokumen.
Nilai Atom
Node tanpa anak atau induk dan turunan dari salah satu tipe data atom bawaan yang ditentukan oleh Skema XML adalah Nilai Atom.
item
Dan, nilai atom atau node yang merupakan tipe data spesifik XQuery disebut Item.
Untuk Apa XQuery Digunakan?
Awalnya, XQuery dirancang sebagai bahasa kueri untuk data yang disimpan dalam bentuk XML. Itu menunjukkan peran kuncinya adalah untuk mendapatkan informasi dari database XML yang mencakup database relasional yang menyimpan data XML atau menyajikan tampilan XML dari data yang mereka pegang.
Selain itu, kita dapat menggunakan XQuery untuk memanipulasi dokumen XML yang berdiri sendiri. Misalnya, menuju transformasi pesan yang lewat di antara aplikasi. Khususnya, di sini, XQuery bersaing langsung dengan XSLT, dan memilih bahasa sebagian besar merupakan masalah preferensi pribadi.
Meskipun dapat dikatakan, beberapa orang juga menggunakannya untuk merender XML menjadi HTML untuk presentasi. Dan ini menunjukkan popularitasnya yang besar juga. Namun, ini bukan pekerjaan yang dirancang untuk XQuery, tetapi orang cenderung menemukan cara baru untuk menggunakannya.
Apa yang Dilakukan XQuery?
Seperti yang kita ketahui, XQuery adalah bahasa fungsional yang kita gunakan untuk menemukan dan mengekstrak elemen dan atribut dari dokumen XML. Dan selain itu, ia memiliki beberapa contoh penggunaan seperti:
Untuk mengekstrak informasi untuk digunakan dalam layanan web
Untuk menghasilkan laporan ringkasan
Untuk mengubah data XML menjadi XHTML
Karakteristik XQuery
Bahasa Fungsional: Untuk mengambil/meminta data berbasis XML.
Analog dengan SQL: Apa SQL untuk database, XQuery adalah XML.
Berbasis XPath: Untuk menavigasi dokumen XML, XQuery menggunakan ekspresi XPath.
Diterima secara universal: Semua database utama mendukung XQuery.
Bahasa pemrograman berorientasi ekspresi: XQuery adalah bahasa pemrograman berorientasi ekspresi dengan sistem tipe sederhana.
Standar W3C: Ini adalah standar W3C.
XQuery adalah Tentang Meminta XML
Untuk menemukan dan mengekstrak elemen dan atribut dari dokumen XML, bahasa XQuery diturunkan.
Aturan Sintaks Dasar XQuery
Di sini, kami mencantumkan beberapa aturan sintaks dasar:
Hal – hal sensitif.
Elemen, variabel, dan atribut XML harus berupa nama XML yang valid.
Nilai string, dalam XQuery, bisa dalam tanda kutip tunggal atau ganda.
Juga, nama yang diikuti dengan $ saat variabel XQuery ditentukan, seperti $bookstore.
Selain itu, komentarnya dibatasi dengan (: dan :). Misalnya- (: Komentar XQuery 🙂
XQuery dan XPath
Ada fungsi dan operator yang sama dan model data yang sama di XQuery 1.0 dan XPath 2.0. Mengetahui XPath saat mempelajari XQuery sangat bermanfaat.
Mengubah Dokumen XML Menggunakan XQuery
Lembar gaya XSL dan XQuery sangat mirip. Keduanya dapat mengubah input XML ke format lain. Dan, ketika kita mendefinisikan skenario transformasi, kita perlu menentukan URL input. Dimungkinkan untuk menyimpan dan membuka hasil di aplikasi terkait. Kami bahkan dapat menjalankan prosesor FO pada output XQuery.
Di antara banyak file XQuery, skenario transformasi dapat dibagikan, dan juga diekspor bersama dengan skenario XSLT.
Selanjutnya, mereka dapat dikelola di kotak dialog Configure Transformation Scenario atau tampilan Scenarios. Transformasi dapat dijalankan pada dokumen XML yang ditentukan dalam bidang URL XML, atau dokumen yang dirujuk dari ekspresi kueri jika bidang ini kosong.
Transformasi parameter XQuery harus diatur dalam kotak dialog Parameter. Selain itu, parameter yang ada di namespace harus ditentukan menggunakan nama yang memenuhi syarat.
Ekspresi XQuery FLWOR
Pengucapan untuk FLWOR adalah “bunga”. Di sini F singkatan dari “Untuk,” L untuk “Biarkan,” W untuk “Di mana,” O untuk “Pesan oleh,” R untuk “Kembali.” Ini didefinisikan sebagai:
For – Ini memilih urutan node.
Biarkan – Ini mengikat urutan ke variabel.
Dimana – Ini menyaring node.
Order by – Ini mengurutkan node.
Kembali – Akhirnya, apa yang harus dikembalikan dievaluasi sekali untuk setiap node
Beberapa Keuntungan dari XQuery
Tidak heran bahwa menggunakan XQuery bermanfaat untuk semua. Jadi, di sini kami mencantumkan beberapa keunggulan utama XQuery, seperti:
- Dimungkinkan untuk mengambil data hierarkis dan tabular dengan XQuery.
- Kita dapat menggunakan XQuery untuk menanyakan struktur grafik & struktur pohon.
- Untuk mengubah dokumen XML menjadi dokumen XHTML, kita dapat menggunakan XQuery.
- Selain itu, ini memungkinkan kita untuk bekerja dalam satu model umum apa pun jenis data yang kita kerjakan: XML, relasional, atau data objek.
- Untuk kueri yang mewakili hasil sebagai XML, untuk kueri XML yang disimpan di dalam atau di luar database, serta untuk menjangkau sumber relasional dan XML, XQuery sangat ideal.
- Selain itu, ini memungkinkan kita untuk membuat berbagai jenis representasi XML dari data yang sama.
- Dengan menggunakan XQuery, kita dapat mengkueri sumber relasional dan sumber XML. Juga, seseorang dapat membuat satu hasil XML.
- Kita bisa langsung menggunakan XQuery untuk query halaman web.
- Seseorang dapat membangun halaman web menggunakan XQuery.
- Dimungkinkan untuk mengubah dokumen XML melalui XQuery.
Untuk database berbasis XML dan database berbasis objek, XQuery sangat ideal. Nah, dibandingkan dengan database tabular murni, database objek jauh lebih fleksibel dan kuat.
Kesimpulan
Oleh karena itu, kita telah melihat bahwa XQuery bertindak seperti bahasa ekspresi karena menentukan aliran data dan operasi yang tepat untuk mencapai hasil yang diinginkan.
Dan kita telah melihat bahwa ini adalah spesifikasi untuk bahasa kueri yang memungkinkan pengguna atau pemrogram untuk mengekstrak informasi dari file Extensible Markup Language (XML) dan juga kumpulan data apa pun yang dapat berupa XML. Bahkan sintaksnya dimaksudkan agar mudah digunakan serta dipahami.
![]()
![]()
![]()
![]()
![]()

Pelajari XQuery dalam 10 Menit
Pelajari XQuery dalam 10 Menit – Tutorial XQuery ini untuk semua orang yang benar-benar ingin tahu apa itu XQuery, tetapi tidak punya waktu untuk mencari tahu. Kita semua tahu masalahnya: begitu banyak teknologi baru yang menarik, begitu sedikit waktu untuk menelitinya. Sejujurnya, saya harap Anda akan menghabiskan lebih dari sepuluh menit pada tutorial XQuery ini — tetapi jika Anda benar-benar harus segera meninggalkannya, saya harap Anda tetap mempelajari sesuatu yang berguna.
Pelajari XQuery dalam 10 Menit
Untuk Apa XQuery?
zorba-xquery.com – XQuery dirancang terutama sebagai bahasa kueri untuk data yang disimpan dalam bentuk XML. Jadi peran utamanya adalah untuk mendapatkan informasi dari database XML — ini termasuk database relasional yang menyimpan data XML, atau yang menyajikan tampilan XML dari data yang mereka pegang.
Beberapa orang juga menggunakan XQuery untuk memanipulasi dokumen XML yang berdiri sendiri, misalnya, untuk mengubah pesan yang lewat di antara aplikasi. Dalam peran itu XQuery bersaing langsung dengan XSLT, dan bahasa mana yang Anda pilih sebagian besar merupakan masalah preferensi pribadi.
Faktanya, beberapa orang sangat menyukai XQuery sehingga mereka bahkan menggunakannya untuk merender XML menjadi HTML untuk presentasi. Itu bukan benar-benar pekerjaan yang dirancang untuk XQuery, dan saya tidak akan merekomendasikan orang untuk melakukan itu, tetapi begitu Anda mengenal alat, Anda cenderung menemukan cara baru untuk menggunakannya.
Baca Juga : Memahami Alat Bantu Pencarian EAD sebagai Data : XQuery untuk Pengarsip
Bermain dengan XQuery
Cara terbaik untuk belajar tentang apa pun adalah dengan mencobanya sendiri. Dua cara Anda dapat mencoba contoh XQuery dalam artikel ini adalah:
Instal Stylus Studio – Lalu buka File > New > XQuery File… dan Anda dapat mulai membuat kueri di panel editor. (Di Stylus Studio, Anda juga dapat menggunakan XQuery mapper visual untuk membuat kueri Anda secara grafis. Jika Anda menyukai pendekatan itu, silakan. Tapi saya akan berkonsentrasi di sini pada sintaks bahasa yang sebenarnya.)
Unduh DataDirect XQuery – komponen pemrosesan XQuery berbasis Java untuk menanyakan data relasional, file XML, dan data non-XML menggunakan XQuery.
(Antara Anda dan saya, jika Anda hanya punya waktu sepuluh menit, Anda tidak akan punya waktu untuk menginstal perangkat lunak baru, jadi teruskan membaca …)
XQuery Pertama Anda
Jika Anda ingin tahu bagaimana melakukan Hello World! di XQuery, ini dia
Ini adalah cara kerjanya di Stylus Studio:
- Pilih File > Baru > File XQuery …
- Masukkan kueri (seperti di atas) ke panel pengeditan
- Pilih File > Save As … dan pilih nama file
Klik tombol Hasil Pratinjau
Game untuk sesuatu yang lebih menarik?
Untuk yang satu itu, tentunya jarak tempuh bisa berbeda-beda. Ketepatan nilai waktu (fraksi detik) bergantung pada prosesor XQuery yang Anda gunakan, dan zona waktu (5 jam sebelum GMT dalam kasus ini) bergantung pada bagaimana sistem Anda dikonfigurasi.
Tak satu pun dari ini adalah pertanyaan yang sangat berguna, tentu saja, dan apa yang mereka tunjukkan bukanlah ilmu roket. Tetapi dalam bahasa kueri, Anda harus dapat melakukan sedikit perhitungan, dan XQuery telah membahasnya. Lebih lanjut, XQuery dirancang sedemikian rupa sehingga ekspresi sepenuhnya dapat disarang — ekspresi apa pun dapat digunakan dalam ekspresi lain apa pun, asalkan memberikan nilai tipe yang tepat — dan ini berarti bahwa ekspresi yang terutama ditujukan untuk memilih data dalam klausa where juga dapat digunakan sebagai kueri yang berdiri sendiri dengan hak mereka sendiri.
Mengakses Dokumen XML dengan XQuery
Meskipun mampu menangani tugas-tugas biasa seperti yang dijelaskan di bagian sebelumnya, XQuery dirancang untuk mengakses data XML. Jadi mari kita lihat beberapa kueri sederhana yang memerlukan dokumen XML sebagai inputnya.
Dokumen sumber yang akan kita gunakan disebut videos.xml. Ini didistribusikan sebagai file contoh dengan Stylus Studio, dan Anda akan menemukannya di suatu tempat seperti c:\Program Files\Stylus Studio 2008 XML Enterprise Suite\examples\VideoCenter\videos.xml
Ada juga salinan file contoh ini di Web.
XQuery memungkinkan Anda untuk mengakses file secara langsung dari salah satu lokasi ini, menggunakan URL yang sesuai sebagai argumen untuk fungsi doc()-nya. Inilah XQuery yang hanya mengambil dan menampilkan seluruh dokumen:
doc(‘file:///c:/Program%20Files/Stylus%20Studio%206%20XML%20Profesional %20Edition/examples/VideoCenter/videos.xml’)
Fungsi yang sama dapat digunakan untuk mendapatkan salinan dari Web:
(Ini hanya akan berfungsi jika Anda online, tentu saja; dan jika Anda berada di belakang firewall perusahaan, Anda mungkin harus melakukan beberapa penyesuaian pada konfigurasi Java Anda untuk membuatnya berfungsi.)
URL tersebut agak berat, tetapi ada pintasan yang dapat Anda gunakan:
Jika Anda bekerja di Stylus Studio, klik XQuery / Scenario Properties, dan di bawah Main Input (opsional), telusuri file input dan pilih. Anda sekarang dapat merujuk ke dokumen ini dalam kueri Anda hanya sebagai “.” (dot).
Jika Anda bekerja langsung dengan DataDirect XQuery, saya sarankan Anda menyalin file ke suatu tempat lokal, misalnya c:\query\videos.xml, dan bekerja dengannya dari lokasi itu. Gunakan opsi baris perintah -s c:\query\videos.xml dan Anda akan kembali dapat merujuk ke dokumen dalam kueri Anda sebagai “.” (dot).
File berisi sejumlah bagian. Salah satunya adalah elemen <aktor>, yang bisa kita pilih seperti ini:
Itu adalah pertanyaan “nyata” pertama kami. Jika Anda terbiasa dengan XPath, Anda mungkin mengenali bahwa semua kueri sejauh ini adalah ekspresi XPath yang valid. Kami telah menggunakan beberapa fungsi — current-time() dan doc() — yang mungkin asing karena mereka baru di XPath 2.0, yang masih berupa draft; tetapi sintaks dari semua kueri sejauh ini adalah sintaks XPath biasa. Faktanya, bahasa XQuery dirancang agar setiap ekspresi XPath yang valid juga merupakan kueri XQuery yang valid.
Ini berarti kita juga dapat menulis ekspresi XPath yang lebih kompleks seperti ini:
Sistem yang berbeda mungkin menampilkan output ini dengan cara yang berbeda. Secara teknis, hasil kueri ini adalah urutan dua simpul elemen dalam representasi pohon dari dokumen XML sumber, dan ada banyak cara yang mungkin dipilih sistem untuk menampilkan urutan seperti itu di layar. Stylus Studio memberi Anda pilihan tampilan teks dan tampilan hierarki: Anda menggunakan tombol di sebelah jendela Pratinjau untuk beralih dari satu ke yang lain.
Contoh ini menggunakan fungsi lain — end-with() — yang baru di XPath 2.0. Kami menyebutnya di dalam predikat (ekspresi antara tanda kurung siku), yang mendefinisikan kondisi yang harus dipenuhi oleh node agar dapat dipilih. Ekspresi XPath ini memiliki dua bagian: path .//actors/actor yang menunjukkan elemen mana yang kita minati, dan predikat [berakhir dengan(., ‘Lisa’)] yang menunjukkan pengujian yang harus dipenuhi oleh node. Predikat dievaluasi sekali untuk setiap elemen yang dipilih; dalam predikat, ekspresi “.” (titik) mengacu pada simpul yang sedang diuji predikatnya, yaitu aktor yang dipilih.
Tanda “/” di jalur informal berarti “turun satu tingkat”, sedangkan “//” berarti “turun berapa pun tingkatnya”. Jika jalur dimulai dengan “./” atau “.//” Anda dapat mengabaikan inisial “.” (ini mengasumsikan bahwa pemilihan dimulai dari atas pohon, yang selalu terjadi dalam contoh kita). Anda juga dapat menggunakan konstruksi seperti “/..” untuk naik satu tingkat, dan “/@id” untuk memilih atribut. Sekali lagi, ini semua akan akrab jika Anda sudah tahu XPath.
XPath mampu melakukan beberapa pilihan yang cukup kuat, dan sebelum kita beralih ke XQuery yang tepat, mari kita lihat contoh yang lebih kompleks. Misalkan kita ingin mencari judul semua video yang menampilkan aktor yang bernama depan Lisa. Setiap video dalam file diwakili oleh elemen video seperti ini:
Sekali lagi, ini adalah XPath murni (dan karena itu XQuery yang valid). Anda dapat membacanya dari kiri ke kanan sebagai:
Mulai dari dokumen yang dipilih secara implisit (videos.xml)
Pilih semua elemen <video> di level mana pun
Pilih yang memiliki elemen actorRef yang nilainya sama dengan salah satu nilai berikut:
- Pilih semua elemen <aktor> di level mana pun
- Pilih semua elemen anak <actor> mereka
- Pilih elemen hanya jika nilainya diakhiri dengan ‘Lisa’
- Pilih nilai atribut id
- Pilih elemen anak <title> dari elemen <video> yang dipilih ini
Banyak orang menemukan bahwa pada tingkat kerumitan ini, sintaks XPath menjadi agak membingungkan. Faktanya, contoh ini hanya tentang memperluas XPath hingga batasnya. Untuk jenis kueri ini, dan untuk hal yang lebih rumit, sintaks XQuery menjadi miliknya sendiri. Tetapi perlu diingat bahwa ada banyak hal sederhana yang dapat Anda lakukan dengan XPath saja, dan bahwa setiap ekspresi XPath yang valid juga valid di XQuery. Perhatikan bahwa Stylus Studio juga menyediakan penganalisis XPath bawaan untuk mengedit dan menguji ekspresi XPath yang kompleks secara visual, dan mendukung versi 1.0 dan 2.0.
Ekspresi XQuery FLWOR
Jika Anda telah menggunakan SQL, maka Anda akan mengenali contoh terakhir sebagai gabungan antara dua tabel, tabel video dan tabel aktor. Ini tidak persis sama dalam XML, karena datanya lebih hierarkis daripada tabel, tetapi XQuery memungkinkan Anda untuk menulis kueri gabungan dengan cara yang mirip dengan pendekatan SQL yang sudah dikenal. Setara dengan ekspresi SELECT SQL disebut ekspresi FLWOR, dinamai berdasarkan lima klausanya: for, let, where, order by, return. Berikut contoh terakhir, kali ini ditulis ulang sebagai ekspresi FLWOR:
Dan tentu saja, kami mendapatkan hasil yang sama.
Mari kita bongkar ekspresi FLWOR ini:
Klausa let hanya mendeklarasikan variabel. Saya telah menyertakan ini di sini karena ketika saya menerapkan kueri, saya mungkin ingin mengatur variabel ini secara berbeda; misalnya, saya mungkin ingin menginisialisasinya ke doc(‘videos.xml’), atau ke hasil beberapa kueri kompleks yang menempatkan dokumen dalam database.
Klausa for mendefinisikan dua variabel rentang: satu memproses semua video secara bergantian, yang lain memproses semua aktor secara bergantian. Secara keseluruhan, ekspresi FLWOR memproses semua kemungkinan pasangan video dan aktor.
Klausa where kemudian memilih pasangan yang benar-benar kita minati. Kita hanya tertarik jika aktor muncul di video itu, dan kita hanya tertarik jika nama aktor diakhiri dengan ‘Lisa’.
Akhirnya klausa pengembalian memberi tahu sistem informasi apa yang ingin kita dapatkan kembali. Dalam hal ini kami ingin judul video.
Jika Anda telah mengikuti dengan cermat, Anda mungkin telah memperhatikan satu trik XPath kecil yang kami pertahankan dalam kueri ini. Sebagian besar video akan menampilkan lebih dari satu aktor (walaupun database khusus ini tidak mencoba untuk membuat katalog pemain bit-part). Oleh karena itu, ekspresi $v/actorRef memilih beberapa elemen. Aturan untuk operator = di XPath (dan karena itu juga di XQuery) adalah bahwa ia membandingkan semua yang ada di sebelah kiri dengan semua yang ada di sebelah kanan dan mengembalikan nilai true jika setidaknya ada satu kecocokan. Akibatnya, itu melakukan gabungan implisit. Jika Anda ingin menghindari pemanfaatan fitur ini, dan untuk menulis kueri Anda dalam bentuk relasional yang lebih klasik, Anda dapat menyatakannya sebagai:
Kali ini saya telah menggunakan operator kesetaraan yang berbeda, eq, yang mengikuti aturan yang lebih konvensional daripada = tidak: ini secara ketat membandingkan satu nilai di sebelah kiri dengan satu nilai di sebelah kanan. (Tapi seperti perbandingan dalam SQL, ia memiliki aturan khusus untuk menangani kasus di mana salah satu nilai tidak ada.)
Bagaimana dengan “O” di FLWOR? Itu ada di sana sehingga Anda bisa mendapatkan hasil dalam urutan yang diurutkan. Misalkan Anda ingin video dalam urutan tanggal rilis mereka. Inilah kueri yang direvisi:
Dan jika Anda bertanya-tanya mengapa itu bukan ekspresi LFWOR: klausa for dan let dapat muncul dalam urutan apa pun, dan Anda dapat memiliki jumlah masing-masing. Itu, dan LFWOR tidak benar-benar jatuh dari lidah, sekarang bukan?. Ada lebih banyak lagi ekspresi FLOWR daripada apa yang tercakup dalam tutorial singkat XQuery ini — untuk informasi lebih lanjut, pastikan untuk melihat tutorial XQuery FLWOR.
Menghasilkan Output XML dengan XQuery
Sejauh ini semua kueri yang kami tulis telah memilih node dalam dokumen sumber. Saya telah menunjukkan hasilnya seolah-olah sistem menyalin node untuk membuat semacam dokumen hasil, dan jika Anda menjalankan DataDirect XQuery dari baris perintah dari dalam Stylus Studio, itulah yang terjadi; tapi itu hanya mode eksekusi default. Dalam aplikasi nyata Anda ingin mengontrol bentuk dokumen keluaran, yang mungkin menjadi masukan untuk aplikasi lain — mungkin masukan untuk transformasi XSLT atau bahkan kueri lainnya.
XQuery memungkinkan struktur dokumen hasil untuk didefinisikan menggunakan notasi seperti XML. Berikut adalah contoh yang menyempurnakan kueri kami sebelumnya dengan beberapa markup XML:
Saya juga telah mengubah kueri sehingga nama depan aktor sekarang menjadi parameter. Ini membuat kueri dapat digunakan kembali. Cara parameter diberikan bervariasi dari satu prosesor XQuery ke yang lain. Di Stylus Studio, pilih XQuery > Scenario Properties; klik tab Parameter Values, dan Anda akan melihat ruang untuk memasukkan nilai parameter. Masukkan “Lisa”, dalam tanda kutip (Stylus Studio mengharapkan ekspresi, jadi jika Anda mengabaikan tanda kutip, nilai ini akan diambil sebagai referensi ke elemen bernama <Lisa>).
Jika Anda menjalankan DataDirect XQuery dari baris perintah, beginilah tampilan outputnya sekarang:
(Bukan kueri yang dirancang dengan baik, karena kedua video tersebut menampilkan aktris yang berbeda, keduanya bernama Lisa; tetapi jika sepuluh menit Anda belum habis, mungkin Anda dapat memperbaikinya sendiri.)
Tunjukkan Basis Datanya!
Saya mulai dengan mengatakan bahwa tujuan utama XQuery adalah untuk mengekstrak data dari database XML, tetapi semua contoh saya telah menggunakan satu dokumen XML sebagai input.
Orang terkadang memeras kumpulan data besar (misalnya, direktori telepon perusahaan) ke dalam satu dokumen XML, dan memprosesnya sebagai file tanpa memanfaatkan sistem basis data apa pun. Ini bukan sesuatu yang saya sarankan secara khusus, tetapi jika volume data tidak melebihi beberapa megabita dan tingkat transaksinya sederhana, maka itu sangat mungkin dilakukan. Jadi contoh dalam pendahuluan ini tidak sepenuhnya tidak realistis.
Namun, jika Anda memiliki database nyata, bentuk kueri tidak perlu banyak berubah dari contoh-contoh ini. Alih-alih menggunakan fungsi doc() (atau cukup “.”) untuk memilih dokumen, Anda mungkin akan memanggil fungsi collection() untuk membuka database, atau kumpulan dokumen tertentu di dalam database. Cara sebenarnya untuk menamai koleksi mungkin berbeda dari satu sistem basis data ke sistem basis data lainnya. Hasil dari fungsi XQuery collection() adalah sekumpulan dokumen (lebih tepatnya, urutan dokumen, tetapi urutannya tidak terlalu penting), dan Anda dapat memprosesnya menggunakan ekspresi jalur atau ekspresi FLWOR dengan cara yang sama seperti Anda menangani satu dokumen.
Ada lebih banyak database daripada melakukan kueri, tentu saja. Setiap produk memiliki caranya sendiri dalam menyiapkan database, mendefinisikan skema, memuat dokumen, dan melakukan operasi pemeliharaan seperti pencadangan dan pemulihan. XQuery saat ini hanya menangani satu bagian kecil dari pekerjaan. Di masa mendatang kemungkinan juga akan ada pembaruan XQuery, tetapi sementara itu setiap vendor menentukan sendiri.
Salah satu fitur yang sangat bagus dari XQuery adalah ia memiliki potensi untuk menggabungkan data dari beberapa database (dan dokumen XML yang berdiri sendiri). Jika itu sesuatu yang Anda minati, DataDirect XQuery™, yang mendukung akses ke Oracle, DB2, SQL Server, Sybase, MySQL, dan banyak Basis Data Relasional lainnya.
Waktunya habis!
Selamat telah menyelesaikan tutorial XQuery ini. Seperti yang mungkin Anda duga, ada lebih banyak hal di XQuery daripada yang sempat kami sajikan dalam primer XQuery singkat ini. Untuk bacaan lebih lanjut, lihat banyak tutorial XQuery lainnya yang tersedia secara gratis di situs web ini.
Jika Anda ingin segera mengotori tangan Anda, Stylus Studio menyediakan banyak alat XQuery, termasuk editor XQuery, XQuery Debugger dengan dukungan terintegrasi untuk DataDirect XQuery, XQuery Mapper untuk mengembangkan proyek XQuery secara visual, dan XQuery Profiler untuk benchmarking dan mengoptimalkan ekspresi XQuery. Yang terbaik dari semuanya, Stylus Studio menyediakan beberapa demonstrasi video online untuk membuat Anda mengenal alat ini dan alat lainnya, dan Anda dapat mencoba Stylus Studio secara gratis.
Terakhir, jika Anda lebih tertarik secara akademis, Anda dapat menemukan spesifikasi XQuery itu sendiri . Sebagai dokumen standar, sebenarnya cukup mudah dibaca, dan memiliki banyak contoh. Spesifikasi adalah bagian dari rakit dokumen di XQuery, yang semuanya terdaftar di bagian Referensi, tetapi yang mungkin sangat berguna bagi Anda adalah spesifikasi Fungsi dan Operator xpath-fungsi. Dokumen ini mencantumkan semua fungsi di pustaka XQuery, tetapi peringatan — hanya fn: yang diawali secara langsung tersedia untuk pengguna akhir. (Anda akan sering melihat pengguna XQuery menulis awalan fn:, tetapi itu tidak pernah diperlukan.)
![]()
![]()
![]()
![]()
![]()
Memahami Alat Bantu Pencarian EAD sebagai Data : XQuery untuk Pengarsip
Memahami Alat Bantu Pencarian EAD sebagai Data : XQuery untuk Pengarsip – XQuery adalah bahasa scripting yang sederhana, namun kuat, yang dirancang untuk memungkinkan penggunatanpa pelatihan pemrograman formal untuk mengekstrak, mengubah, dan memanipulasi data XML.Selain itu, bahasanya adalah standar yang diterima dan rekomendasi W3C seperti standar saudaranya, XML dan XSLT. Dengan kata lain, raison d’etre XQuery bertepatansempurna dengan kebutuhan arsiparis saat ini.
Memahami Alat Bantu Pencarian EAD sebagai Data : XQuery untuk Pengarsip
zorba-xquery.com – Berikut ini adalah penjelasan singkat, pragmatis,ikhtisar XQuery untuk arsiparis yang akan memungkinkan arsiparis dengan pemahaman yang tajam XML, XPath, dan EAD untuk mulai bereksperimen dengan memanipulasi data EAD menggunakan Pengarsip tidak perlu dijual di XML – repositori di seluruh negeri memiliki menjadi pengadopsi awal teknologi sejak 1990-an. Pada dasarnya semua data arsip standar telah baik dikembangkan untuk XML (EAD) atau telah diadaptasi untuk penggunaannya (MARK). Keterbukaan, standarisasi, fleksibilitas struktural, dan kemudahan penggunaan telah membuktikan bahwa XML adalah alat yang kuat dan sentral bagi arsiparis abad ke-21. Namun, sementara arsiparis telah lama menyimpan alat bantu pencarian di EAD, ada perbedaan keterampilan utama antara menyandikan alat bantu pencarian dan benar-benar melakukan apa saja dengan data itu.i Cara paling umum arsiparis telah memanfaatkan data XML melalui lembar gaya XSLT, seringkali untuk menampilkan data dalam daftar panjang yang dapat digulir.
Baca Juga : Keterampilan dan Kode HTML Zorba Xquery Processor
Baru-baru ini, ada gerakan untuk lebih berkembang sistem informasi arsip yang canggih dan mudah digunakan.ii Selanjutnya, arsip yang telah banyak berinvestasi dalam mengembangkan alat bantu pencarian EAD akan senang untuk mengotomatisasi menggunakan kembali data ini untuk akses yang lebih mudah, kegiatan penjangkauan, dan banyak lagi. Cukup sederhana,memanipulasi dan memformat ulang data XML telah menjadi keterampilan yang berharga bagi arsiparis dan XQuery menyediakan metode sederhana dan mudah dipelajari untuk melakukan hal itu.Ini sama sekali bukan pengenalan yang komprehensif untuk XQuery – untuk itu,arsiparis perlu mencari sumber daya yang lebih tradisional seperti yang disediakan di akhir artikel ini. Namun, memulai dengan studi XQuery yang panjang dan komprehensif mungkin hanya bermanfaat untuk menunda pengalaman langsung dan membuat frustrasi orang yang tidak sabar. Pengarsip mungkin merasa lebih mudah menyelam dan bereksperimen dengan bahasa sebelum mencari pemahaman yang lebih luas.
Yang dibutuhkan arsiparis adalah panduan sederhana dan mudah diakses untuk memulainya. Jika Anda mengalami masalah saat menggunakan panduan ini, coba cari masalah Anda baik di Stack Overflow atau dengan mesin pencari favorit Anda.iii
XQuery dan XSLT
Sekarang, untuk arsiparis yang memiliki pengalaman dengan XSLT, XQuery terdengar sebagai sangat mirip dengan transformasi lembar gaya XML ini. XSLT juga dapat digunakan untuk mengubah dan memanipulasi data XML, digunakan secara luas jauh sebelum XQuery, dan memiliki keuntungan dikompilasi oleh browser web. Ini berarti data XML dapat diproses sisi server dengan XSLT sedangkan browser saat ini tidak dapat membaca XQuery tanpa pengaya khusus atau solusi. Pengarsip tidak harus belajar dan beradaptasi dengan yang baru perangkat lunak untuk mencoba XSLT – mereka baru saja bereksperimen dengan transformasi stylesheet dengan menggunakan browser web yang mereka kenal. Ini mungkin mengapa XSLT telah menikmati lebih banyak kegunaan dalam komunitas arsip.
Sekolah pascasarjana umumnya mengajarkan XSLT dan banyak arsiparis telah menghabiskan banyak waktu untuk mempelajari standar tersebut. Belum,sementara XSLT dan XQuery tumpang tindih dalam beberapa hal, ada beberapa perbedaan penting yang membuat yang terakhir lebih berguna dalam banyak kasus.
Mengapa XQuery?
Jadi mengapa menggunakan atau mempelajari XQuery? Yang terpenting, ini jauh lebih sederhana dan lebih murah verbose dari XSLT, yang ditulis dalam XML itu sendiri. Ini membuat XSLT membutuhkan lebih banyak karakter untuk melakukan tindakan yang sama dari XQuery (lihat lampiran untuk perbandingan).
Meskipun ini tidak tampak seperti keuntungan besar, itu sebenarnya. Skrip XQuery lebih bersih,lebih sederhana, seringkali lebih cepat untuk ditulis, dan lebih mudah dirawat. Ini membuat pengguna banyak lebih mungkin untuk benar-benar menggunakan bahasa tersebut dan lebih efektif menggunakan data XML mereka.
Seperti yang dikatakan Steve Krug tentang pengujian kegunaan: jika suatu tugas sulit, itu akan menjadi dihindari, sedangkan jika suatu tugas lebih mudah, semakin besar kemungkinan akan dilakukan lebih banyak frequent.iv Pengarsip yang menghindari memperbarui file XSLT besar yang diturunkan sejak lama dari buku masak EAD asli pasti akan bersimpati.v
Kedua, XQuery lebih kuat dari XSLT. Itu dapat melakukan lebih banyak fungsi dan membuat tugas yang kompleks menjadi lebih mudah. Fungsi adalah inti dari kedua bahasa – anggap mereka sebagai kata-kata ajaib yang telah diprogram sebelumnya yang membantu pengguna untuk dengan mudah melakukan tindakan kompleks dengan data mereka. Di XQuery, pengguna tingkat lanjut bahkan dapat menulis fungsi mereka sendiri dengan lebih mudah daripada di XSLT. Sementara XSLT 3.0 telah memperkenalkan lebih banyak fungsi, ini bahkan tidak sebanding ke XQuery yang memiliki 225 fungsi bawaan yang dapat dengan mudah memeriksa apakah suatu elemen ada atau berisi data, mengedit string karakter dengan cara yang rumit, menentukan posisi relatif elemen, dan banyak lagi alat yang memungkinkan pengguna mendapatkan hasil maksimal dari data mereka.
Jadi, XQuery memungkinkan arsiparis untuk berbuat lebih banyak dengan data mereka, dan membuatnya lebih banyak lebih mungkin untuk melakukannya. Namun, keuntungan terbesarnya mungkin memaksa mereka untuk memikirkan File EAD sebagai data bukan sebagai daftar atau indeks. Tidak seperti XSLT, XQuery dirancang untuk query XML – itu dirancang agar pengguna menanyakan data apa yang mereka inginkan dan bagaimana mereka menginginkannya. Ini akan memaksa arsiparis untuk melihat deskripsi mereka sebagai unit informasi yang terpisah. Tidak hanya melakukan deskripsi memiliki hubungan kontekstual dengan deskripsi sekitarnya yang menyampaikan urutan asli, tetapi juga berguna untuk mengembalikan deskripsi terpisah sebagai hasil pencarian atau menyusun ulang data untuk menampilkan informasi dengan cara yang berbeda (dan mungkin lebih mudah diakses).
Ini konsisten dengan argumen baru-baru ini bahwa alat bantu pencarian EAD tingkat tunggal berguna sebagai elemen diskrit untuk navigasi dan secara keseluruhan akan berfungsi untuk menjauhkan EAD dari tampilan yang peneliti lihat.vi Dengan demikian, EAD akan menjadi penyimpan data arsip deskripsi sementara antarmuka tambahan atau sistem informasi menanyakannya daripada mengubah atau memformat ulang itu
Apa yang Saya Perlukan untuk Menggunakan XQuery?
Meskipun XQuery tidak dapat berjalan secara native di browser umum, ada sejumlah cara untuk mulai bereksperimen dengan query XML. Pertama, Saxon juga memproses Xquery sebagai XSLT, jadi jika Anda memiliki akses ke perangkat lunak desktop seperti Oxygen XML Editor atau server yang menjalankan Saxon, Anda harus dapat menjalankan kueri seperti Anda menjalankan XSLT.vii Saxon juga dapat diatur untuk dijalankan di desktop menggunakan Java Runtime Environment meskipun garis komando. Selain itu, eXist-db adalah database XML open source yang dibuat secara khusus untuk menjalankan XQuery dengan arsitektur RESTful – pada dasarnya, eXist dimaksudkan untuk menjadi bagian dari bagian belakang dari layanan web biasa.
viii Di sini perangkat lunak berjalan di server (atau disimulasikan menggunakan Java Runtime Environment) dan pengguna masuk ke antarmuka web untuk mengunggah dan mengelola data XML. Skrip XQuery kemudian dapat dijalankan di dalam halaman web oleh pengguna akhir. Sejak HTML adalah XML itu sendiri, dengan eXist XQuery dapat mengedit, mengubah, dan meminta HTML dan fungsi seperti bahasa scripting sisi server. Alat Bantu Pencarian Perpustakaan Universitas Princeton memanfaatkan eXist-db. Akhirnya, Zorba adalah prosesor XQuery yang dapat dijalankan dalam perintah line atau sebagai ekstensi ke PHP atau Python.ix Ini memungkinkan XQuery dijalankan di dalam server- samping aplikasi web PHP atau Python.
Metode di atas untuk menjalankan skrip XQuery mungkin tampak menakutkan atau membingungkan bagi banyak arsiparis, terutama mereka yang memiliki sedikit pengalaman dengan server dan web Arsitektur. Ini, dibandingkan dengan dukungan browser asli, tampaknya menjadi salah satu alasannya XSLT tetap populer. Namun, ada juga cara yang lebih mudah dan lebih mudah diakses untuk bereksperimen dengan XQuery. Lagi pula, itu hanya teks.
Mungkin cara termudah untuk mulai bermain dengan XQuery adalah menggunakan BaseX, a database XML open-source yang dikembangkan secara komunal dengan antarmuka GUI desktop.x Kebanyakan penting, BaseX adalah platform independen dan dapat diinstal pada Windows terbaru atau mesin desktop Mac seperti program pada umumnya. Program ini juga berlisensi BSD, artinya gratis untuk diunduh dan digunakan dengan atribusi. Hal terbaik tentang BaseX GUI adalah kesederhanaannya. Secara default, antarmuka memiliki empat panel utama, atau jendela: Editor panel, yang menyertakan panel Proyek untuk memilih file; panel Info Kueri; dan Hasil panel Panel Editor dan Hasil paling penting bagi pengguna baru yang mungkin kewalahan dengan melihat terlalu banyak bagian belakang. Panel Editor berfungsi seperti editor teks dasar: Skrip XQuery dapat ditulis secara manual dan file dapat dibuka atau disimpan menggunakan ikon. Setelah skrip ditulis, pengguna dapat menekan ikon “Jalankan kueri”,yang terlihat seperti simbol putar, dan hasilnya muncul di panel Hasil. Ini dia hasil dapat disimpan atau ditimpa oleh hasil baru dengan menjalankan kueri lain.
Ini kesederhanaan memungkinkan untuk percobaan dan kesalahan yang mudah, penting bagi arsiparis yang tidak berpengalaman dengan pemrograman untuk bereksperimen dengan memanipulasi data Mempelajari Bahasa, Struktur, dan Sintaks Ada dua bagian skrip XQuery: prolog dan badan. prolognya adalah opsional, muncul sebelum isi, dan bertindak seperti header untuk mendeklarasikan ruang nama, variabel dan beberapa bagian struktural dari hasil XML seperti encoding.
Sejak tujuan bagian ini adalah untuk membuat arsiparis memulai dengan XQuery secepat dan semudah mungkin, kami hanya akan mendeklarasikan versi dan dokumen input di prolog kami Baris pertama menentukan versi skrip XQuery dan baris kedua mendeklarasikan variabel $docas file EAD yang ingin kita kueri. Variabel bisa tunggal apa saja kata tanpa spasi yang diawali dengan tanda dolar ($). Kita bisa dengan mudah gunakan $ead, $xml, atau apa pun yang kita suka sebagai pengganti $doc. Doc () berikutnya di baris kedua adalah bukan variabel, tetapi fungsi yang secara khusus membaca dokumen xml. Pengguna juga dapat ganti fungsi doc() dengan collection() dan arahkan ke folder alih-alih file. Ini akan menetapkan beberapa file dalam direktori ke variabel $doc. Setiap pernyataan di prolog diikuti oleh titik koma (;), dan setelah pernyataan prolog terakhir, badan kueri dimulai.
Sekarang ketika kita mengkueri variabel $doc nanti di body, BaseX akan mengetahuinya yang kami maksud adalah file EAD kami.Di badan kueri ada dua jenis pernyataan utama yang paling sering Anda gunakan sering: ekspresi FLOWR dan ekspresi IF. FLOWR adalah singkatan dari For, Let, Order by, Di mana, dan Kembali – kemungkinan pertanyaan yang akan Anda ajukan tentang data Anda (pada dasarnya siapa,apa, di mana, mengapa, dan kapan). Berikut adalah contoh ekspresi FLOWR untuk menanyakan EAD mengajukan Untuk adalah bagian pertama dari ekspresi FLOWR, anggap itu sebagai “untuk masing-masing,” sebagai sisa dari ekspresi akan dilakukan pada setiap tag yang ditemukan di jalur yang diberikan. Pernyataan ini mencari setiap tag <c01> dalam daftar penampung dalam variabel $doc (file EAD kami) dan menetapkan setiap tag yang ditemukannya ke variabel $series. Kami baru saja memilih setiap level teratas seri dari file EAD kami. Baris kedua mendeklarasikan variabel lain ($extent) ke mewakili isi dari setiap tag <extent> seri di dalam tag <did> dan <physdesc>-nya. Baris ketiga di mana pernyataan membatasi semua tag <c01> ke hanya mereka yang memiliki atribut “level” dengan nilai “seri” (<c01 level=”series”/>). Itu baris keempat memerintahkan setiap tag <c01> yang tersisa oleh variabel ($extent) yang dideklarasikan dalam baris dua. Di departemen kami, tag <extent> berisi luas setiap seri dalam kaki kubik, jadi baris ini mengurutkan ulang setiap tag <c01> berdasarkan jangkauannya. Akhirnya, baris keempat mengembalikan hasil.
Kita bisa meminta untuk mengembalikan $series saja, tetapi itu juga akan mengembalikan setiap tag <c01> nya isi – termasuk tag <did> dan komponen yang lebih rendah dalam daftar penampung. Jadi kami hanya akan menanyakan secara spesifik untuk setiap judul tag <c01>. Hasil dari kueri ini akan kembali setiap judul seri diurutkan berdasarkan ukuran. Pengarsip yang ingin bereksperimen dengan XQuery harus salin dan tempel kode ini ke panel Editor BaseX dan arahkan jalur di prolog ke sebuah berkas EAD. Selanjutnya Anda harus bereksperimen dengan menghapus beberapa kode dan menambahkannya secara bertahap ke lihat bagaimana setiap perubahan mengubah hasil. Ekspresi FLOWR hanya membutuhkan satu dari baik untuk atau membiarkan dan kembali.
Sekarang kita juga dapat menambahkan tag XML kita sendiri ke hasil, membedakan dari kueri kembali dengan tanda kurung kurawal ({ dan }). Ini sangat menambah utilitas XQuery tetapi juga memperkenalkan beberapa kompleksitas tambahan. Jika kita memasukkan kueri ini ke BaseX, kita akan menyadari bahwa ekspresi ini menghasilkan
setiap seri juga mempertahankan tag <unittitle> aslinya. Menggunakan fungsi data() hanya akan mengembalikan konten dari tag yang dipilih. Ganti baris terakhir pada kode di atas dengan baris di sini:
kembalikan <FileSeries>{data($series/did/unittitle)}</FileSeries> Fungsi adalah kata-kata ajaib yang membuat XQuery begitu kuat. Mereka melakukan tindakan pada isi di dalam kurungnya. Sejauh ini kami telah menggunakan dua fungsi: data( ) dan doc() di prolog kami. Standar XQuery 3.0 mencakup 225 fungsi bawaan dan lebih banyak lagi tersedia di situs web Pustaka Fungsi FunctX XQuery.xi Seringkali,tempat paling sederhana untuk memasukkan fungsi-fungsi ini adalah dalam klausa let. Di sini kita memiliki yang sama query dengan penambahan fungsi huruf besar().
Kueri ini mendeklarasikan variabel baru $UPPERseries yang melakukan function huruf besar() pada judul variabel $series lama kita. Saat kami mengembalikan yang baru variabel itu akan di semua huruf kapital. Selain ekspresi FLOWR, pengguna Xquery akan sering menggunakan ekspresi IF. Ekspresi ini berguna untuk membuat kondisi yang menerima sejumlah besar variabilitas yang sering ada dalam data arsip.
versi xquery “3.0”;
mendeklarasikan variabel $doc := doc(path/ke/EAD.xml);
if ($doc/ead/archdesc/did/physdesc/extent < 20)
lalu (<size>{data($doc/ead/archdesc/did/physdesc/extent)}</size>)
else (<size>Koleksi ini banyak.</size>)
Di baris pertama ekspresi IF ini di badan XQuery menguji apakah koleksi lebih kecil dari 20 kaki kubik. Baris kedua dan ketiga menawarkan dua opsi yang bergantung apakah baris pertama benar atau tidak. Kueri mengembalikan tingkat koleksi atau teks yang menyatakan koleksinya besar. Anda mungkin mendapatkan kesalahan jika file EAD yang Anda gunakan mengandung lebih dari satu angka dalam tag <extent>. Coba bereksperimen dengan mengubah kurang dari operator (<) menjadi lebih besar dari (>), sama (=), atau tidak sama (!=) operator. Ekspresi IF yang lebih kompleks mungkin menghasilkan hasil yang berbeda jika wadah EAD daftar memiliki lebih dari satu atau dua tingkat pengaturan.
![]()
![]()
![]()
![]()
![]()
Keterampilan dan Kode HTML Zorba Xquery Processor
Keterampilan dan Kode HTML Zorba Xquery Processor: Menurut pengembangan, versi html modern adalah html5, berikut adalah daftar periksa versi html5 terbaru pula.
Keterampilan dan Kode HTML Zorba Xquery Processor
zorba-xquery.com – Zorba Html Processing & Xquery Code Processor: Menurut desain, versi html modern adalah html5, saya menaruh daftar periksa buat versi html5 terbaru di sini. Teks miring, tebal adalah, & teks yang digarisbawahi adalah
. Penanda html wajib berisi sampul seni supaya trik berfungsi, kode atau konten html berikutnya nir dipercaya sebagai perpanjangan penanda. Berikut adalah HTML yang baru saja aku untuk. Pemrosesan & HTML: Di bawah ini merupakan HTML penuh warna menurut kode hex dan rgb.
Soal & Pembahasan mekanika glbb 2012 kode sbmptn 643 kerja gerak benda secara grafis menggambarkan hubungan antara kecepatan & saat misalnya terlihat dalam gambar di bawah ini. Html adalah markup hypertext yg menelusuri sejarah pengembangan kode html dari versi paling awal sampai waktu ini. Banyak fitur html5 tidak memerlukan Adobe Flash buat memutar video. Andika siswoyo & joko susilo (berganti nama), kedua nama ini muncul pada tag paragraf. Html, kependekan berdasarkan Hypertext Markup Language, merupakan bahasa web atau markup Internet yang terdiri menurut kombinasi teks & keterangan dalam bentuk karakter atau kode untuk dimasukkan ke pada arsip buat menciptakan halaman web.
Baca Juga : Pola Desain XQuery Digunakan Komunitas Berorientasi Objek
Editor HTML ini jua mempunyai pemilih rona yang berguna buat menyesuaikan gaya HTML & kursor yg memberikan warta saat mengarahkan kursor ke kode eksklusif. HTML dikompilasi menjadi kode & simbol eksklusif yg dimasukkan ke dalam file atau dokumen. Pengerjaan & kode HTML: apabila seluruh fitur di atas tidak ada, Anda masih dapat menambahkan fitur lain dengan memasang perluasan pilihan Anda berdasarkan pasar. Saya sudah membuat 2 model menurut pengolahan & kode html/kode html pada atas. Bahasa pengkodean ini digunakan pada Internet. Menggunakan addeventlistener kode html dapat javascript gratis. Codeigniter xssdp net google dan work and html code/bootstrap template integration bermanfaat.
Bahkan, kemungkinan besar Anda tidak memerlukan perangkat lunak buat menulis kode html, dan poly desainer web mengklaimnya.
Html adalah bahasa markup buat Internet (web) dalam bentuk kode & simbol yg dimasukkan ke dalam file buat ditampilkan secara internal. Dalam kode JavaScript di atas kami memakai 2 metode addeventlistener buat setiap tombol. Javascript berinteraksi pribadi menggunakan pengguna di sisi klien. Apabila Anda masih mempunyai kode atau konten HTML lainnya. Apabila Anda tidak terbiasa menggunakan html, bagian ini bisa memberi Anda beberapa wawasan. Biasanya perintah html link di email merupakan: Hypertext Markup Language (html) adalah bahasa markup yang digunakan buat membuat page web, menampilkan berbagai warta pada browser web, dan hanya memformat hypertext yg ditulis pada arsip format ASCII buat: Menciptakan bentuk yang halus. Namun sampai beberapa tahun kemudian, nir ada proses baku. Editor HTML ini pula mempunyai pemilih rona yang membantu Anda menyesuaikan gaya HTML Anda, dan fungsi hover yang memberikan keterangan saat Anda mengarahkan kursor ke kode tertentu. Ini juga mempunyai penyorotan sintaks buat menunjukkan kepada Anda apa arti kode ketika ini. Dabblet menyediakan lembar kerja terpisah buat bekerja menggunakan html, css & js. Tidak terdapat kode khusus, cukup tempel kode css atau html & rekatkan kode dalam mode buat. Lihat langkah 2 buat petunjuk. Semua kode html wajib ditulis pada tag html.
Tindakan & kode html: Tindakan & kode html: Deskripsi singkat mengenai html & kode. Hypertext Markup Language (html) merupakan bahasa markup yang digunakan untuk menciptakan halaman web, menampilkan berbagai warta pada browser Internet, & hanya memformat hypertext yang ditulis pada file ASCII buat membuat tampilan format terpadu. Pengertian html adalah Web Markup Language & html merupakan singkatan menurut Hypertext Markup Language. Setelah bekerja menggunakan
dan mengetahui arti kode html/html dan memakai html. Bahkan, kemungkinan akbar Anda nir memerlukan software buat menulis kode html, dan poly desainer web mengklaimnya. HTML dikompilasi menjadi kode & simbol eksklusif yang dimasukkan ke pada file atau dokumen. Bagian ini tidak menaruh petunjuk buat mengedit kode html. Pengodean & kode HTML. Ini juga mempunyai penyorotan sintaks buat menerangkan pada Anda apa arti kode waktu ini. Dabblet menyediakan lembar kerja terpisah buat bekerja dengan html, css & js. Jika Anda masih mempunyai kode atau konten HTML lainnya. Cara menampilkan postingan blog.
Html disusun menggunakan kode & simbol tertentu yang dimasukkan ke dalam sebuah file atau dokumen. Bagi anda yang belum mengenal html, berikut merupakan pengertian html konklusi pengertian html. Pengerjaan & kode html : Dalam kode javascript diatas, saya menggunakan 2 buah method addeventlistener, buat setiap tombol. Tanpa panjang lebar langsung saja inilah beberapa tag html dasar yang tidak jarang diaplikasikan buat mendesain website beserta fungsi & model penggunaannya. Berikut kode warna html lengkap menurut kode hexadecimal & kode rgb. Pengerjaan & kode html : Pengerjaan & kode html : Html editor ini juga mempunyai color picker yang berguna buat mengatur style html & mouse hover yg memberikan anda informasi ketika mengarahkan kursor ke kode tertentu. Html hingga saat ini adalah standar pada internet yang didefinisikan &. Dan setiap halaman kode akbar akan masuk ke struktur ini selesainya pemangkasan. Penanda html harus memuat penutup supaya trik bisa bekerja & kode atau konten html yang terdapat setelahnya tidak dipercaya sebagai lanjutan dari penanda. Home » unlabelled » pengerjaan & kode html / dalam kode html diatas, saya membangun dua buah contoh.
Pengerjaan & kode html : Pengerjaan & kode html / dalam kode html diatas, saya membentuk 2 butir model. Kode rona html (hypertext markup language) ditandai memakai enam karakter sesudah tagar (#), misalnya #000000. Sebagai catatan, seluruh kode html harus ditulis didalam tag html. Html adalah singkatan dari hypertext markup language.
Home » unlabelled » pengerjaan & kode html / pada kode html diatas, aku menciptakan dua butir contoh. Mengenal html adalah singkatan menurut hypertext markup languange merupakan bahasa web atau markup internet yang menurut dari kombinasi antara text & liputan berupa simbol atau kode yang akan dimasukan kedalam suatu file guna menciptakan suatu laman situs. Untuk petunjuk, lihat langkah 2: Pengerjaan & kode html / selesainya mengetahui pengertian html & kegunaan html. Javascript melakukan hubungan menggunakan pengguna langsung disisi klien. Menyertakan kode css atau html dalam konten postingan yang berupa tutorial harus menggunakan kode khusus agar nantinya kode tadi tidak terbaca menjadi bagian dari kode template sebagai akibatnya sanggup ditampilkan secara terpisah menyerupai teks biasa. Pengerjaan & kode html : Pengerjaan & kode html / integrasi template bootstrap memakai codeigniter xssdp net google is good for you :
Jika Anda kehilangan seluruh fitur pada atas, Anda masih dapat menambahkan fitur lain dengan menginstal ekstensi yang dapat Anda pilih pada toko. Kualitas hukuman dan kode html: Html adalah markup hypertext, berikut merupakan sejarah pengembangan kode html berdasarkan versi awal hingga waktu ini. Saya telah menciptakan 2 contoh berdasarkan pengolahan & kode html/kode html pada atas. Perintah tautan email HTML tipikal merupakan: Kode HTML terdiri menurut kode dan karakter tertentu yang disematkan pada sebuah arsip atau dokumen. Bahasa html umumnya disediakan sebagai kode yang disebut . Pengertian html Apa itu html? Tetapi, Anda perlu menulis metode addeventlistener setelah mengirim kode html ke browser web. Dalam kode JavaScript di atas kami memakai 2 metode addeventlistener buat setiap tombol. Pengertian html merupakan Web Markup Language dan html adalah singkatan berdasarkan Hypertext Markup Language. Pengerjaan & kode HTML: Menempelkan kode CSS atau HTML tanpa menggunakan kode spesifik apa pun, dan menempelkan kode dalam mode pembuatan apa pun.
Menurut desainnya, html versi terbaru merupakan html5 dan ini merupakan daftar periksa html5 versi terbaru. Berikut merupakan kode warna html lengkap menurut kode hex dan kode rgb. Jadi Anda perlu menempatkannya setelah kode html Anda. Rekatkan kode html ke laman. Ini pula memiliki penyorotan sintaks buat menerangkan kepada Anda apa arti kode ketika ini. Dabblet menyediakan lbr kerja terpisah untuk bekerja dengan html, css & js.
Kode warna Hypertext Markup Language (html) ditandai menggunakan hashtag (#) diikuti dengan 6 karakter (contohnya #000000). Editor HTML ini juga memiliki pemilih rona yang membantu Anda menyesuaikan gaya HTML Anda, & fungsi hover yang memberikan kabar saat Anda mengarahkan kursor ke kode eksklusif. Pengertian html merupakan Web Markup Language dan html adalah singkatan berdasarkan Hypertext Markup Language. Dalam kode JavaScript di atas kami menggunakan 2 metode addeventlistener buat setiap tombol. Apabila Anda nir memiliki semua fitur pada atas, Anda masih bisa menambahkan fitur lain menggunakan menginstal perluasan pilihan Anda dari pasar. Deskripsi singkat tentang html & kode.
HTML adalah bahasa markup Internet (web) pada bentuk kode dan simbol yang dimasukkan ke dalam file buat tampilan internal. Rekatkan kode html ke halaman. Html adalah singkatan dari Hypertext Markup Language. Pengertian html merupakan Web Markup Language dan html merupakan singkatan dari Hypertext Markup Language. Apabila Anda tidak terbiasa menggunakan html, bagian ini mungkin memberi Anda beberapa wawasan. Misalnya, jika Anda menciptakan teks miring atau miring, page html akan menulis buat teks miring, buat teks tebal, dan buat teks yang digarisbawahi. Untuk menulis, semua kode html harus ditulis pada tag html. Jadi Anda perlu menempatkannya selesainya kode html Anda. Penanda html harus berisi sampul seni agar trik berfungsi, kode atau konten html berikutnya tidak dipercaya sebagai perpanjangan penanda.
Tetapi sampai beberapa tahun lalu, nir terdapat proses standar. Html adalah singkatan dari Hypertext Markup Language. Ini pula mempunyai penyorotan sintaks buat menerangkan pada Anda apa arti kode saat ini. Dabblet menyediakan lembar kerja terpisah buat bekerja menggunakan html, css & js. Pengerjaan & Kode HTML: Pengenalan HTML, kependekan dari Hypertext Markup Language, adalah bahasa web atau markup Internet yang terdiri berdasarkan kombinasi teks dan fakta pada bentuk karakter atau kode buat dimasukkan ke pada file buat menciptakan situs web. Halaman. Rekatkan kode html ke halaman. Tanpa basa-basi lagi, berikut adalah beberapa tag html dasar yg acapkali dipakai pada desain situs web, bersama fitur dan model penggunaannya. Editor HTML ini juga mempunyai pemilih warna yang membantu Anda menyesuaikan gaya HTML Anda, dan fungsi hover yg menaruh berita saat Anda mengarahkan kursor ke kode tertentu. Pada artikel ini, kita akan membahas beberapa tag html dasar. Banyak fitur html5 tidak memerlukan Adobe Flash buat memutar video.
Lihat langkah 2 buat petunjuk. Anda kini pula dapat menggunakan Html5 buat membuat pelaksanaan lintas platform misalnya Android, iOS, Windows Phone. Pengertian html Apa itu html? Bagian ini nir menaruh petunjuk buat mengedit kode html. Setelah memakai html buat mengetahui pengerjaan dan arti berdasarkan kode html/html. Dan semua laman kode besar masuk ke struktur ini selesainya dipangkas. Baris kode di atas menerapkan latar belakang biru, paragraf 20px, & font “biru sedang” ke laman HTML yg sama. Bagian ini tidak menaruh petunjuk buat mengedit kode html. Menggunakan addeventlistener kode html dapat javascript perdeo. Bekerja dan kode html:
apabila Anda menambah panjang pegas Javascript, Anda berinteraksi pribadi dengan pengguna di sisi klien. Jadi Anda perlu menempatkannya sehabis kode html Anda. Html merupakan, hingga saat ini, baku web seperti yang didefinisikan sang dan. Untuk menyematkan kode Google Survei ke laman web, Anda perlu mengedit kode html halaman.
![]()
![]()
![]()
![]()
![]()

Pola Desain XQuery Digunakan Komunitas Berorientasi Objek
Pola Desain XQuery Digunakan Komunitas Berorientasi Objek – desain banyak digunakan dalam komunitas berorientasi objek. Ini adalah solusi yang terbukti, matang, dan dapat digunakan kembali yang membuat pengembangan modul menjadi mudah dengan kopling minimal. Pola desain juga merupakan konstruksi tingkat tinggi yang membantu meningkatkan interaksi antar pengembang. Saat ini, XQuery dan rangkaian spesifikasinya melampaui pengumpulan kueri dan dokumen XML. XQuery semakin banyak digunakan sebagai bahasa pemrograman multi-paradigma. Tujuan artikel ini adalah untuk membenarkan kebutuhan pola desain XQuery menggunakan contoh aplikasi dunia nyata dan untuk mengeksplorasi keberadaan solusi desain umum untuk masalah berulang dalam aplikasi XQuery skala besar.
Pola Desain XQuery Digunakan Komunitas Berorientasi Objek
pengantar
zorba-xquery.com – Selama dekade terakhir, pola desain telah menjadi semakin populer di komunitas berorientasi objek sebagai solusi generik yang dapat digunakan kembali untuk masalah desain perangkat lunak yang lazim. Hampir semua aplikasi, komponen, atau API yang ditulis dalam bahasa berorientasi objek saat ini dibangun menggunakan pola desain. Pola-pola ini meningkatkan pengembangan perangkat lunak di
Perangkat Lunak dan Desain yang Dapat Digunakan Kembali. Pola desain seringkali merupakan kunci untuk enkapsulasi yang lebih baik dan pengurangan kopling. antar komponen perangkat lunak. Akibatnya, perangkat lunak yang mewakili pola desain dapat digunakan kembali, fleksibel, dan dapat diperluas.
Dokumen: Menggunakan nama template dalam dokumentasi perangkat lunak memungkinkan pengembang untuk langsung mengenali/mengingat struktur dan struktur API.
Komunikasi dan Pembelajaran: Pola desain adalah bahasa umum untuk meningkatkan komunikasi antara pengembang perangkat lunak dan analis. Kosakata yang mapan juga memfasilitasi diskusi di antara pengembang dari berbagai bahasa pemrograman.
Pola desain diterima secara luas dan diterapkan di komunitas berorientasi objek, tetapi jarang dikenali di luar komunitas. Misalnya, dalam dunia fungsional tidak dievaluasi pada tingkat pemrograman aplikasi yang kompleks. “Pola Desain Logika Fungsional” [AntoyHanus02FLOPS] mengevaluasi pola desain sebagai bahasa fungsional untuk memecahkan masalah spesifik pada tingkat yang sangat rendah. Saat berdiskusi di level meta. Dari perspektif ini, ketakutan Tom DeMarco tahun 1996 terbukti masuk akal.
“Saya khawatir pengembang perangkat lunak di luar komunitas objek akan mengabaikannya karena pola desain mengklaim hanya tertarik pada perangkat lunak berorientasi objek. Ini akan menjadi canggung. Semua pengembang perangkat lunak menggunakan pola. Pemahaman yang lebih baik tentang abstraksi yang dapat digunakan kembali dalam pekerjaan kami hanya dapat membantu dalam hal ini.”
Baca Juga : Tujuan Umum Zorba – Prosesor XQuery Yang Diimplementasikan
Sebagai bahasa fungsional dan deklaratif, XQuery dikembangkan oleh World Wide Web Consortium sebagai bahasa pemrosesan XML tujuan umum yang cocok untuk berbagai arsitektur dan lingkungan. Awalnya, XQuery terutama digunakan untuk query data XML dari sistem database (misalnya [XQueryInAction]), tetapi secara bertahap menjadi bahasa pemrograman aplikasi yang lengkap. Satu skenario di mana XQuery digunakan sebagai bahasa pemrograman lengkap disebut arsitektur XML ujung ke ujung. Dalam arsitektur ini, XML adalah bentuk utama penyimpanan dan pemrosesan informasi. Informasi ini disimpan di seluruh panggilan program yang berurutan, dan XQuery adalah bahasa utama untuk mengakses informasi ini untuk menemukan, memfilter, mengubah, memperbarui, dan membangun alur kerja aplikasi yang lebih kompleks. Juga di dalam program, XQuery diperkenalkan ke layanan web, entitas web seperti Atom, JSON, pesan HTTP, dan metode otentikasi umum seperti OpenID atau OAuth. Bersama dengan spesifikasi ekstensi XQuery Update [XQUF], XQuery Scripting [XQSE] dan XQuery Full Text [XQFT], XQuery saat ini bekerja di liga yang sama dengan bahasa pemrograman tujuan umum seperti Java, Python atau Ruby, tetapi masih di tepian. Dalam hal ekspresi dan dukungan kelas satu untuk menangani sumber daya web.
Secara keseluruhan, perubahan terkini ini secara pribadi terkait menggunakan pertumbuhan pelaksanaan XQuery yg kompleks [Kaufmann2009]. Salah satu model pelaksanaan semacam itu dikembangkan sang pelanggan perusahaan loka penulis bekerja. Aplikasi ini merupakan pelaksanaan Enterprise Resource Planning (ERP) yg seluruhnya ditulis pada XQuery pada atas Server Aplikasi Web Sausalito [Sausalito2010]. Aplikasi ini terdiri menurut 28.000 baris kode XQuery yg diimplementasikan pada 135 modul XQuery. Dengan mengaudit pelaksanaan ini, kami menemukan tanda-tanda generik pada basis kode & proses pengembangan:
Modul mempunyai kopling yg bertenaga antara satu sama lain. Mereka didasarkan dalam kerja sama kompleks yg mengurangi fungsinya balik pada kerangka kerja atau pelaksanaan lain. Dalam kebanyakan kasus, memperluas atau menyusun modul akan memerlukan pemfaktoran ulang kode yg mengganggu.
Beberapa desain struktural berulang dirujuk memakai kosakata yg berbeda. Meskipun mereka bisa dicermati menjadi identik menurut sudut pandang abstrak. Ini menaikkan penghalang masuk ke basis kode secara signifikan.
Seperti yg dijelaskan pada awal bagian ini, kasus misalnya itu sudah dipecahkan pada komunitas berorientasi objek menggunakan berbagi & menerapkan pola desain. Didorong sang pengamatan ini, kami tetapkan buat mulai memakai pola desain buat mengatasi ketidaksesuaian yg dijelaskan pada atas. Selain memotivasi penggunaan pola desain buat XQuery, donasi makalah ini merupakan buat mengidentifikasi ketidaksesuaian pada pelaksanaan global konkret & menerangkan bagaimana ketidaksesuaian ini bisa diperbaiki menggunakan memakai pola desain. Secara khusus, kami menyajikan empat pola desain & menyebutkan bagaimana masing-masing pola tadi memecahkan satu kasus desain eksklusif pada pelaksanaan model (yg sedang berjalan) kami.
Sisa artikel ini disusun sebagai berikut. Bagian 2 menjelaskan kasus penggunaan untuk contoh kerja. Contoh ini digunakan untuk mendemonstrasikan masalah desain yang ada dalam aplikasi dunia nyata. Di masing-masing dari empat bagian berikut (Bagian 3, 4, 5, 6) kami menyajikan pola desain untuk mengatasi salah satu masalah desain yang diidentifikasi. Bagian 7 menyimpulkan dokumen dan memberikan pandangan tentang pekerjaan di masa depan.
Menjalankan Contoh: Aplikasi AtomPub
Protokol Penerbitan Atom (AtomPub; lihat RFC5023) merupakan protokol berbasis HTTP buat menciptakan & memperbarui asal daya pada web. Akhir-akhir ini, sebagai poly dipakai buat mengimplementasikan API buat layanan cloud. Contoh yg paling menonjol mungkin merupakan Protokol Data Google[1]. AtomPub dibangun pada atas Format Sindikasi Atom yg adalah representasi XML berdasarkan deretan asal daya yg berubah-ubah (mis. umpan web). Oleh lantaran itu, XQuery sangat cocok buat mengimplementasikan layanan (cloud) berbasis AtomPub.
Kami memakai pelaksanaan AtomPub buat menyajikan pola desain buat XQuery. Aplikasi ini sangat cocok buat poly pola (umum) lantaran sebagian akbar komponennya wajib bisa dipakai pulang sang komponen pelaksanaan lainnya. Selain itu, memanfaatkan perpustakaan yg ada (contohnya buat komunikasi & otentikasi HTTP) memerlukan beberapa keputusan desain yg cermat buat dibuat. Pada dasarnya, pelaksanaan AtomPub terdiri berdasarkan 2 komponen utama: klien & server. Klien merupakan pelaksanaan XQuery yg wajib mengimplementasikan 2 masalah penggunaan dasar berikut:
Kasus Penggunaan 1: Kirim permintaan HTTP buat menciptakan entri Atom.
Kasus Penggunaan 2: Kirim permintaan HTTP buat merogoh entri Atom tertentu. Entri yg didapatkan wajib diubah sebagai HTML.
Server adalah aplikasi yang berjalan di dalam server aplikasi berkemampuan XQuery. Artinya, fungsi dipicu oleh permintaan HTTP. Fungsi-fungsi ini menggunakan modul (HTTP) yang disediakan oleh server aplikasi untuk mengakses konten permintaan HTTP. Server bertindak sebagai mitra untuk permintaan klien. Secara khusus, Anda harus dapat mengatasi dua kasus penggunaan berikut:
Kasus Penggunaan 3: Terima dan simpan item AtomPub. Anda harus dapat menyimpan item di lokasi mana pun, seperti sistem file atau koleksi XQuery.
Use Case 4: Posting tweet untuk setiap item yang dibuat dalam use case 3. Bagian berikut dari artikel ini menunjukkan cara menggunakan pola desain untuk memecahkan masalah desain yang terkait dengan penerapan kasus penggunaan yang dijelaskan. Kita akan mulai dengan Kasus Penggunaan Klien 1 dan 2 di Bagian 3 dan 4, masing-masing. Bagian 5 dan 6 kemudian menjelaskan desain dan implementasi kasus penggunaan 3 dan 4. Tabel berikut menjelaskan pemetaan kasus penggunaan, bagian, fungsi XQuery yang diperlukan, dan nama template yang digunakan untuk mengimplementasikan fitur tersebut.
Rantai Tanggung Jawab
Pada bagian ini, kita akan membahas implementasi use case 1. Dengan kata lain, saya mencoba mengembangkan program XQuery yang menerbitkan catatan Atom ke server yang mendukung AtomPub. Karena tidak semua orang dapat memublikasikan item, server AtomPub memerlukan otentikasi menggunakan mekanisme otentikasi HTTP Basic. Protokol AtomPub menetapkan untuk menerbitkan item dengan mengirimkan permintaan HTTP POST ke server. Payload permintaan ini berisi item yang akan dipublikasikan. Otentikasi HTTP dasar memerlukan nama pengguna dan kata sandi sebagai bagian dari HTTPHeader. Saya telah memilih untuk mengandalkan klien HTTP EXPpath (standar de facto) (lihat HTTPClient) untuk melakukan panggilan HTTP dari program XQuery saya. Klien HTTP ini bekerja dengan melewatkan elemen XDM yang menjelaskan permintaan ke fungsi yang disebut sendrequest. Untuk mengimplementasikan kasus penggunaan pertama, klien AtomPub dapat diimplementasikan dengan ketergantungan kabel antara modul yang bertanggung jawab untuk membuat dan mengirim permintaan HTTP dan modul yang bertanggung jawab untuk otentikasi. Namun, ini jelas membuat klien AtomPub kurang fleksibel dan membuatnya dapat digunakan kembali dalam skenario lain. Misalnya, mengubah mekanisme otentikasi menjadi sesuatu seperti OAuth atau OpenID akan memerlukan perubahan destruktif pada modul AtomPub, jika tidak maka akan membuat basis kode lain yang sangat berlebihan.
Untuk meningkatkan fleksibilitas dan penggunaan kembali aplikasi, kami menetapkan dua persyaratan desain: Klien AtomPub harus dipisahkan dari mekanisme otentikasi
- yang dapat berinteraksi dengannya saat runtime.
- Transport layer, yaitu implementasi spesifik dari klien HTTP.
Untuk memenuhi persyaratan ini, kami mengembangkan klien AtomPub menggunakan pola Rantai Tanggung Jawab. Tujuan dari pola ini adalah untuk:
Kurangi penggabungan antara modul yang berbeda dengan memindahkan dependensi bersarang keluar dari modul dan secara berurutan menggabungkan fungsi dependen ke dalam rantai. Ini melewati elemen ke bawah rantai dan memberikan masing-masing fungsi ini kesempatan untuk memanipulasi atau memanipulasi elemen.
Keterangan
Menerapkan rantai tanggung jawab pada kasus penggunaan kami akan memisahkan kode yang bertanggung jawab untuk mengirim permintaan dan setiap fungsi yang menetapkan permintaan, seperti menyiapkan permintaan ke AtomPub dan menyertakan informasi autentikasi dalam permintaan. Untuk ini kami mendefinisikan anggota berikut:
Request: Mewakili instance XDM dari permintaan HTTP.
Handler: Sebuah fungsi dalam rantai yang menetapkan atau menangani instance permintaan.
Klien: Memulai permintaan, meneruskannya ke semua fungsi dalam rantai, dan mengembalikan hasilnya. Kemampuan penerapan pihak ketiga memudahkan penulisan ulang klien untuk menggunakan strategi autentikasi yang berbeda, misalnya. Secara khusus, ini menghindari hal-hal yang “diketahui” oleh modul perpustakaan yang berbeda, yaitu mereka tidak saling mengimpor.
Penerapan
Bagian ini menjelaskan kemungkinan implementasi use case dengan menerapkan Rantai Pola Tanggung Jawab. Kita akan mulai dengan menjelaskan implementasi klien yang diimplementasikan dalam fungsi yang disebut local:postentry. Kemudian, dua fungsi atompubclient:post dan httpauth:basic dijelaskan. Masing-masing fungsi ini mengambil sebagai parameter pertama elemen kueri yang ditetapkan di badan setiap fungsi. Cuplikan kode di atas mendeklarasikan dan menginisialisasi elemen permintaan HTTP ($request) yang berisi URL server AtomPub. Elemen ini diteruskan melalui rantai fungsi atompubclient:post dan httpauth:basic dan diakhiri dengan panggilan ke fungsi httpclient:sendrequest(). Fungsi terakhir bertanggung jawab untuk mengeksekusi permintaan. Fungsi atompubclient:post() “memijat” elemen permintaan (menggunakan pembaruan XQuery) sesuai dengan spesifikasi AtomPub. Secara khusus, fungsi ini memeriksa apakah metode permintaan HTTP diatur ke POST. Itu juga membangun badan permintaan HTTP untuk mengunduh posting yang akan diterbitkan.
Fungsi httpauth:basic() kemudian menambahkan atribut nama pengguna dan kata sandi ke permintaan dan menetapkan metode otentikasi default. Pedoman Pelaksanaan
Dalam implementasi yang disajikan di bagian terakhir, kami membuat beberapa keputusan untuk membuat artikel lebih mudah dipahami dan meningkatkan keterbacaan kode. Solusi ini tidak esensial atau optimal untuk implementasi rantai tanggung jawab. Jadi pola ini dapat diimplementasikan di XQuery 1.0. Bagian ini menjelaskan beberapa aspek implementasi alternatif.
. Pertimbangan 1. Implementasi klien, pengikatan fungsi terkait menggunakan skrip XQuery. Namun, ada beberapa cara untuk menerapkan rantai. Misalnya, Anda dapat menerapkan rantai menggunakan gaya penerusan lanjutan atau menggunakan serangkaian elemen fungsional yang berjalan secara berurutan.
Catatan 2: Keputusan lain yang saya buat untuk membuat kode lebih mudah dibaca adalah dengan menggunakan fungsi pembaruan XQuery untuk mengimplementasikan fungsi yang relevan (yaitu atompubclient:post dan httpauth:basic). Implementasi alternatif dapat menyalin dan memodifikasi elemen kueri dan mengembalikannya sebagai hasil dari suatu fungsi. Dalam hal ini, klien harus memastikan bahwa elemen yang dikembalikan diteruskan sebagai argumen ke fungsi berikutnya.
![]()
![]()
![]()
![]()
![]()

Tujuan Umum Zorba – Prosesor XQuery Yang Diimplementasikan
Tujuan Umum Zorba – Prosesor XQuery Yang Diimplementasikan – Tujuan dari proyek ini adalah untuk mengeksplorasi perbatasan komponen mana dari sistem manajemen data yang dapat digantikan oleh komponen yang dipelajari. Dalam makalah terbaru berjudul The Case for Learned Index Structures, kami menunjukkan bahwa indeks inti/struktur data dapat dianggap sebagai model: BTree-Index adalah model untuk memetakan kunci ke posisi record dalam array yang diurutkan, Hash- Indeks sebagai model untuk memetakan kunci ke posisi catatan dalam array yang tidak disortir, dan BitMap-Index sebagai model untuk menunjukkan apakah catatan data ada atau tidak. Dengan demikian, semua struktur indeks yang ada dapat diganti dengan jenis model lain, termasuk model pembelajaran mendalam, yang kami sebut indeks yang dipelajari. Hasil awal kami menunjukkan, bahwa dengan menggunakan jaringan saraf, kami mampu mengungguli B-Trees yang dioptimalkan untuk cache hingga 70% dalam kecepatan sambil menyimpan urutan besarnya dalam memori pada beberapa set data dunia nyata.
Tujuan Umum Zorba – Prosesor XQuery Yang Diimplementasikan
zorba-xquery.com – Hasil ini ditampilkan dalam podcast acara data O’Reilly dan mendapat banyak perhatian di media sosial, di mana ia menciptakan komentar seperti “Wow! Ini bisa memiliki manfaat besar >> Kasus untuk Struktur Indeks yang Dipelajari” oleh Kirk Borne, Data Utama Ilmuwan di Booz Allen atau “Makalah ini mengejutkan saya. Saya menghabiskan 100% kuliah dan sekolah pascasarjana pada indeks. Astaga, tidak berpikir itu akan membuang-buang waktu. 😉 #ML memenuhi struktur data tahun 1960-an dan menghancurkannya ” oleh Steven Sinofsky, Mitra Dewan di A16Z dan mantan Presiden Divisi Windows Microsoft.
Namun, mengapa hasil awal kami sangat menjanjikan, banyak tantangan penelitian terbuka tetap ada untuk membuat gagasan itu layak untuk sistem dunia nyata. Namun, jika mungkin untuk mengatasi keterbatasan indeks yang dipelajari saat ini dan memperluas cakupan ke komponen lain (misalnya, optimasi kueri), gagasan untuk mengganti komponen inti dari sistem manajemen data melalui model yang dipelajari memiliki implikasi yang luas untuk desain sistem masa depan. . Yang paling penting, dimungkinkan untuk mengubah kelas kompleksitas dari beberapa algoritma (misalnya, kinerja insert O(log n) dari B-Trees ke O(1)). Demikian pula, komponen yang dipelajari mungkin memungkinkan untuk memanfaatkan GPU/TPU dengan lebih baik untuk sistem.
Mengungkap potensi Big Data untuk jangkauan pengguna yang lebih luas membutuhkan perubahan paradigma dalam algoritme dan alat yang digunakan untuk menganalisis data. Menjelajahi kumpulan data yang kompleks membutuhkan lebih dari sekadar antarmuka pertanyaan dan respons. Idealnya, pengguna dan sistem terlibat dalam “percakapan”, masing-masing pihak memberikan kontribusi terbaiknya. Pengguna dapat menyumbangkan penilaian dan arahan, sementara mesin dapat menyumbangkan kemampuannya untuk memproses sejumlah besar data, dan bahkan mungkin memprediksi apa yang mungkin dibutuhkan pengguna selanjutnya. Bahkan dengan visualisasi yang canggih, mencerna dan menafsirkan kumpulan data yang besar dan kompleks seringkali melebihi kemampuan manusia. Teknik ML dan statistik dapat membantu dalam situasi ini dengan menyediakan alat yang membersihkan, memfilter, dan mengidentifikasi subset data yang relevan. Sayangnya, dukungan untuk ML sering ditambahkan sebagai renungan: tekniknya terkubur dalam kotak hitam dan dieksekusi dengan cara semua-atau-tidak sama sekali. Hasil seringkali membutuhkan waktu berjam-jam untuk dihitung, yang tidak dapat diterima untuk eksplorasi data interaktif. Selain itu, pengguna ingin melihat hasilnya seiring perkembangannya. Mereka ingin menginterupsi, mengubah parameter, fitur, atau bahkan keseluruhan saluran. Dengan kata lain, saat ini Ilmuwan Data masih menggunakan antarmuka batch gaya teks yang sama dari tahun 80-an, sedangkan kita harus mengeksplorasi data lebih seperti yang dibayangkan oleh banyak film dari James Bond hingga Minority Report atau sebagaimana diuraikan dalam Visi Antarmuka Pengguna Microsoft. Meskipun ada beberapa pekerjaan untuk membuat antarmuka yang sangat baru, seperti yang ada di Minority Report, ini sering mengabaikan aspek sistem dan ML, dan tidak benar-benar dapat digunakan dalam praktiknya, sedangkan di sisi lain komunitas sistem cenderung mengabaikan antarmuka pengguna. aspek.
Sebagai bagian dari proyek Northstar, kami membayangkan pendekatan yang benar-benar baru untuk melakukan analitik eksplorasi. Kami berspekulasi bahwa dalam waktu dekat banyak ruang konferensi akan dilengkapi dengan papan tulis interaktif, seperti Microsoft Surface Hub, dan bahwa kami dapat menggunakan papan tulis tersebut untuk menghindari interaksi bolak-balik selama seminggu antara ilmuwan data dan pakar domain. Sebaliknya, kami percaya bahwa keduanya dapat bekerja sama selama satu pertemuan menggunakan papan tulis interaktif semacam itu untuk memvisualisasikan, mengubah, dan menganalisis bahkan data yang paling kompleks di tempat. Pengaturan ini tidak diragukan lagi akan membantu pengguna dengan cepat sampai pada solusi awal, yang dapat disempurnakan lebih lanjut secara offline. Hipotesis kami adalah bahwa kami dapat membuat eksplorasi data lebih mudah bagi pengguna awam sekaligus secara otomatis melindungi mereka dari banyak kesalahan umum. Selanjutnya kami berhipotesis, bahwa kami dapat mengembangkan sistem eksplorasi data interaktif, yang memberikan hasil yang berarti dalam hitungan sub-detik bahkan untuk pipeline ML yang kompleks melalui kumpulan data yang sangat besar. Teknik tersebut tidak hanya akan membuat ML lebih mudah diakses oleh pengguna yang lebih luas, tetapi juga pada akhirnya memungkinkan lebih banyak penemuan dibandingkan dengan pendekatan berbasis batch apa pun.
Network-Attached-Memory (NAM) dibuat karena pengalaman kami dengan Tupleware di klaster perusahaan modern. Kami menemukan, bahwa generasi berikutnya dari jaringan berkemampuan RDMA berkinerja tinggi memerlukan pemikiran ulang mendasar tidak hanya kerangka kerja analitis tetapi juga sistem manajemen basis data terdistribusi (DDBMS) yang lebih tradisional. DDBMS umumnya dirancang dengan asumsi bahwa jaringan adalah hambatan dan karenanya harus dihindari sebisa mungkin. Asumsi ini tidak berlaku lagi. Dengan InfiniBand FDR 4x, bandwidth yang tersedia untuk mentransfer data di seluruh jaringan sama dengan bandwidth satu saluran memori, dan bandwidth meningkat lebih banyak lagi dengan standar EDR terbaru. Selain itu, dengan meningkatnya kemajuan dalam RDMA, latensi transfer meningkat pada kecepatan yang sama. Melalui analisis teoretis dan evaluasi eksperimental, kami menemukan bahwa desain basis data terdistribusi “lama” tidak mampu mengambil keuntungan penuh dari jaringan cepat dan oleh karena itu kami menyarankan desain baru berdasarkan abstraksi baru yang disebut Network-Attached-Memory (NAM). Lebih mengejutkan, kami menemukan bahwa kebijaksanaan umum bahwa transaksi terdistribusi tidak berskala juga tidak lagi berlaku dengan jaringan generasi berikutnya dan desain ulang sistem yang sesuai. Hasil awal kami menunjukkan bahwa kami dapat mencapai 2 juta transaksi terdistribusi yang menakjubkan per detik melalui delapan mesin e5v2 soket ganda dan Infiniband FDR 4x, dibandingkan 32.000 transaksi per detik menggunakan lebih banyak
Sebagai bagian dari proyek Mengukur Ketidakpastian dalam Eksplorasi Data (QUTE), kami mulai mengembangkan teknik untuk secara otomatis mengukur berbagai jenis kesalahan dalam alur eksplorasi data. Tentu saja, ada jenis ketidakpastian yang jelas, yang biasanya divisualisasikan menggunakan batang kesalahan dan dihitung melalui teknik pengambilan sampel. Namun, ada banyak jenis kesalahan lain, yang sering diabaikan. Misalnya, adalah praktik umum bagi ilmuwan data untuk memperoleh dan mengintegrasikan sumber data yang berbeda untuk mencapai hasil yang lebih berkualitas. Namun, bahkan dengan kumpulan data yang dibersihkan dan digabungkan dengan sempurna, dua pertanyaan mendasar tetap ada: (1) Apakah kumpulan data terintegrasi sudah lengkap? (2) Apa dampak dari data yang tidak diketahui (yaitu, tidak teramati) pada hasil kueri? Sebagai langkah pertama dalam proyek QUDE, kami mengembangkan dan menganalisis teknik untuk memperkirakan dampak data yang tidak diketahui (alias, tidak diketahui tidak diketahui) pada kueri agregat. Ide utamanya adalah bahwa tumpang tindih antara sumber data yang berbeda memungkinkan kita untuk memperkirakan jumlah dan nilai item data yang hilang. Anehnya, teknik statistik kami bebas parameter dan tidak mengasumsikan pengetahuan sebelumnya tentang distribusi. Melalui analisis teoretis dan serangkaian eksperimen, kami menunjukkan bahwa memperkirakan dampak yang tidak diketahui yang tidak diketahui sangat berharga untuk menilai hasil kueri agregat melalui sumber data terintegrasi. Untuk proyek ini, kami bekerja sama dengan Center of Evidence-Based Medicine (EBM) di Brown University.
MLbase: Pembelajaran mesin (ML) dan teknik statistik adalah kunci untuk mengubah data besar menjadi pengetahuan yang dapat ditindaklanjuti. Terlepas dari keunggulan data modern, kompleksitas algoritme ML yang ada sering kali membuat kewalahan|banyak pengguna tidak memahami trade-o s dan tantangan dalam membuat parameter dan memilih di antara teknik pembelajaran yang berbeda. Selain itu, sistem skalabel yang ada yang mendukung pembelajaran mesin biasanya tidak dapat diakses oleh peneliti ML tanpa latar belakang yang kuat dalam sistem terdistribusi dan primitif tingkat rendah. Dalam karya ini, kami menyajikan visi kami untuk MLbase, sistem baru yang memanfaatkan kekuatan pembelajaran mesin untuk pengguna akhir dan peneliti ML. MLbase menyediakan (1) cara deklaratif sederhana untuk menentukan tugas ML, (2) pengoptimal baru untuk memilih dan mengadaptasi pilihan algoritme pembelajaran secara dinamis, dan (3) seperangkat operator tingkat tinggi untuk memungkinkan peneliti ML mengimplementasikan berbagai metode ML tanpa pengetahuan sistem yang mendalam.
Tupleware: Kerangka kerja analitik saat ini (mis., Hadoop, Spark, dan Flink) dirancang untuk memproses kumpulan data besar yang didistribusikan di seluruh kelompok besar. Asumsi ini mewakili masalah yang dihadapi oleh perusahaan Internet raksasa tetapi mengabaikan kebutuhan pengguna biasa. Perusahaan non-teknologi seperti bank dan pengecer—atau bahkan ilmuwan data biasa—jarang mengoperasikan penyebaran ribuan mesin, alih-alih lebih memilih cluster yang lebih kecil dengan perangkat keras yang lebih andal. Faktanya, survei industri baru-baru ini melaporkan bahwa median cluster Hadoop memiliki kurang dari sepuluh node, dan lebih dari 65% pengguna mengoperasikan cluster yang lebih kecil dari 50 node. Selain itu, meskipun data mentah mungkin sangat besar, setelah langkah pembersihan dan prapemrosesan pertama, model ML data yang dilatih jarang berukuran lebih dari 1-2 TB dan mudah masuk ke memori utama cluster modern. Menargetkan beban kerja analitik yang kompleks pada kluster yang lebih kecil secara mendasar mengubah cara kita mendesain alat analitik.
Dengan Tupleware, kami membangun kerangka kerja analitis pertama khusus untuk pengguna “normal”, bukan Google dan Facebook. Arsitektur Tupleware menyatukan ide-ide dari database, compiler dan komunitas jaringan untuk menciptakan solusi end-to-end yang kuat untuk analisis data yang mengkompilasi alur kerja fungsi yang ditentukan pengguna ke dalam program terdistribusi. Salah satu kontribusi utama Tupleware adalah aturan pengoptimalan hibrid baru, yang menggabungkan pengoptimalan tingkat rendah yang biasanya dilakukan oleh kompiler dengan pengoptimalan kueri tingkat tinggi yang digunakan basis data, untuk mengoptimalkan alur kerja analitis secara otomatis guna memanfaatkan perangkat keras modern dengan lebih baik. Hasil awal kami menunjukkan bahwa untuk tugas ML umum, Tupleware dapat mencapai peningkatan kinerja hingga tiga kali lipat dibandingkan sistem alternatif, seperti Spark atau Hadoop.
Baca Juga : Informasi XQuery Ke Editor Design Studio
Performance Insightful Query Language (PIQL)
Aplikasi web yang baru dirilis sering kali mengalami “Bencana Sukses”, di mana mesin database yang kelebihan beban dan menghasilkan waktu respons yang tinggi menghancurkan pengalaman pengguna yang sebelumnya baik. Sayangnya, independensi data yang disediakan oleh database relasional tradisional, meskipun berguna untuk pengembangan yang cepat, hanya memperburuk masalah dengan menyembunyikan kueri yang berpotensi mahal di bawah ekspresi deklaratif sederhana. Akibatnya, pengembang aplikasi ini semakin meninggalkan database relasional demi kode imperatif yang ditulis terhadap penyimpanan kunci/nilai terdistribusi, kehilangan banyak manfaat dari independensi data dalam prosesnya. Sebagai gantinya, kami mengusulkan PIQL, bahasa deklaratif yang juga memberikan independensi skala dengan menghitung batas atas jumlah operasi penyimpanan kunci/nilai yang akan dilakukan untuk kueri apa pun. Digabungkan dengan model prediksi kepatuhan tujuan tingkat layanan (SLO) dan arsitektur basis data PIQL yang skalabel, batasan ini memudahkan pengembang untuk menulis aplikasi yang toleran terhadap keberhasilan yang mendukung sejumlah besar pengguna sambil tetap memberikan kinerja yang dapat diterima.
Penempatan Multi-Penyewaan yang Sadar Kegagalan
Bersama dengan SAP dan Hasso-Plattner-Institute, saat ini kami sedang menjajaki teknik baru dan algoritme penjadwalan untuk menempatkan aplikasi multi-tenancy di cloud. SAP menjadi penyedia perangkat lunak sebagai layanan dengan platform sesuai permintaan mereka, Business by Design. Layanan SAP baru tersebut menawarkan hosting aplikasi multi-tenant dengan ketersediaan yang sangat kuat dan jaminan waktu respons. Saat ini, jaminan tersebut terutama dicapai dengan menyediakan perangkat keras untuk layanan secara berlebihan. Tujuan dari proyek ini adalah untuk mengembangkan teknik baru dan algoritma penjadwalan, yang lebih hemat biaya, sambil tetap menjamin kesepakatan tingkat layanan bahkan di hadapan kegagalan besar.
Membangun Database di Infrastruktur Cloud
Dengan proyek ini, kami mengeksplorasi peluang dan batasan penggunaan komputasi awan sebagai infrastruktur untuk aplikasi basis data berbasis web untuk keperluan umum. Bagian dari pekerjaan ini adalah untuk menganalisis arsitektur client-server dan pengindeksan alternatif serta protokol konsistensi alternatif. Selanjutnya, kami mengusulkan paradigma transaksi baru, Consistency Rationing, yang tidak hanya mendefinisikan jaminan konsistensi pada data alih-alih pada tingkat transaksi, tetapi juga memungkinkan untuk mengalihkan jaminan konsistensi secara otomatis saat runtime. Dengan demikian, sistem memungkinkan untuk beradaptasi dan menyeimbangkan konsistensi dengan cepat terhadap kemungkinan risiko inkonsistensi. Hasil dari pekerjaan ini diterbitkan di SIGMOD08 dan VLDB09 dan sebagian dikomersialkan oleh 28msec Inc.
Cloudy/Smoky – penyimpanan terdistribusi dan layanan streaming di cloud
Komputasi awan telah mengubah pandangan tentang manajemen data dengan berfokus terutama pada biaya, fleksibilitas dan ketersediaan daripada konsistensi dan kinerja dengan harga berapa pun seperti yang dilakukan DBMS tradisional. Akibatnya, penyimpanan data cloud berjalan pada perangkat keras komoditas, dirancang agar dapat diskalakan, mudah dirawat, dan sangat toleran terhadap kesalahan, sering kali memberikan jaminan konsistensi yang santai. Keberhasilan toko bernilai kunci seperti Amazon S3 atau berbagai sistem sumber terbuka mencerminkan perubahan ini. Solusi yang ada, bagaimanapun, masih kekurangan fungsionalitas substansial yang disediakan oleh DBMS tradisional (misalnya, dukungan untuk transaksi dan bahasa kueri deklaratif) dan disesuaikan dengan skenario spesifik yang menciptakan hutan layanan. Artinya, pengguna harus memutuskan untuk layanan tertentu dan kemudian dikunci ke dalam layanan ini, mencegah evolusi aplikasi, yang mengarah pada penyalahgunaan layanan dan migrasi mahal ke layanan lain. Selama waktu saya di ETH, kami mulai membangun basis data kami sendiri yang sangat skalabel, yang menyediakan arsitektur yang sepenuhnya termodulasi dan tidak disesuaikan dengan kasus penggunaan tertentu. Misalnya, Cloudy mendukung pemrosesan aliran, serta SQL dan permintaan nilai kunci sederhana. Proyek ini dilanjutkan di ETH dan saya masih terlibat sebagian dalam pengembangan.
Zorba – prosesor XQuery tujuan umum yang diimplementasikan di C++
Zorba adalah prosesor XQuery tujuan umum yang diimplementasikan dalam C++ keluarga spesifikasi W3C. Pemroses kueri telah dirancang untuk dapat disematkan di berbagai lingkungan seperti bahasa pemrograman lain yang diperluas dengan kemampuan pemrosesan XML, browser, Database server, pengirim pesan XML, atau ponsel cerdas. Arsitekturnya menggunakan desain modular, yang memungkinkan penyesuaian prosesor kueri Zorba dengan kebutuhan lingkungan. Secara khusus, arsitektur prosesor kueri memungkinkan penyimpanan XML yang dapat dipasang (misalnya memori utama, penyimpanan DOM, penyimpanan besar berbasis disk persisten, penyimpanan S3). Zorba dapat diakses melalui API dari bahasa berikut: C, C++, Ruby, Python, Java, dan PHP. Zorba berjalan di sebagian besar platform dan tersedia di bawah lisensi Apache v2. Bagian saya dalam proyek ini adalah desain dan implementasi dari main
![]()
![]()
![]()
![]()
![]()
Informasi XQuery Ke Editor Design Studio
Informasi XQuery Ke Editor Design Studio – Secara umum, cara Anda memasukkan informasi XQuery ke editor di Oracle Communications Design Studio adalah sama, apa pun editornya. Kontrol XQuery di Oracle Communications Design Studio umumnya memiliki tiga tab: XQuery, Instances, dan Information. Berikut ini adalah instruksi umum untuk memasukkan informasi XQuery ke setiap tab ini di Design Studio.
Informasi XQuery Ke Editor Design Studio
Menggunakan Tab XQuery
zorba-xquery.com – The XQuery tab memungkinkan Anda untuk mengkonfigurasi aturan atau elemen berbasis XQuery, atau mengidentifikasi sumber aturan atau elemen berbasis XQuery. Pilih salah satu opsi berikut:
Pilih Tidak Ada jika konfigurasi XQuery bersifat opsional dan tidak dikonfigurasi. Saat Anda memilih opsi ini, Design Studio menonaktifkan opsi yang tersisa di subtab.
Pilih Ekspresi dan masukkan ekspresi XQuery di kotak teks yang sesuai. Klik Edit untuk membuka kotak dialog Edit XQuery, yang menampilkan ekspresi XQuery yang dikonfigurasi dalam kotak teks yang lebih besar dan dapat diubah ukurannya. Anda dapat mengedit ekspresi di kotak dialog Edit XQuery dan klik OK untuk menyimpan perubahan Anda, atau klik Batal untuk mengabaikan kotak dialog tanpa menyimpan perubahan.
Baca Juga : Pengertian Dan Cara Kerja XQuery
Pilih File untuk menunjukkan bahwa konfigurasi XQuery terletak di file yang disimpan ke direktori sumber daya proyek . Opsi ini memungkinkan Anda untuk menulis ekspresi XQuery Anda menggunakan aplikasi pengeditan XQuery yang telah Anda instal di lingkungan Eclipse Anda. Lihat topik Bantuan online Eclipse Mengasosiasikan editor dengan tipe file untuk informasi lebih lanjut.
Klik Pilih untuk membuka kotak dialog Pilih File XQuery, yang menampilkan semua file XQuery yang terdapat dalam direktori sumber daya proyek . Pilih file XQuery yang sesuai dan klik OK .
Pilih URI untuk menunjukkan bahwa konfigurasi XQuery terletak di lokasi URI jarak jauh.
Klik Properti untuk membuka tampilan Properti, di mana Anda dapat menentukan informasi berikut untuk XQuery:
Anotasi: Elemen anotasi XML opsional memungkinkan Anda memberikan informasi tentang XQuery. Masukkan informasi (misalnya, informasi berformat HTML) untuk sistem eksternal ke dalam bidang <appinfo> Anotasi . Masukkan informasi untuk pengguna manusia ke dalam bidang <dokumentasi> Anotasi .
Bahasa: Saat Anda bekerja dengan beberapa bahasa, Anda dapat memilih bahasa yang berbeda untuk menampilkan deskripsi dan anotasi. Untuk informasi selengkapnya, lihat “Menentukan Preferensi Bahasa” di Bantuan Proses OSM Modeling .
Menggunakan Tab Instance
Anda bisa menentukan perilaku Instance Data untuk mendapatkan data yang tidak disertakan dalam data pesanan dan membuat data tersebut tersedia untuk aturan. Klik Tambahkan untuk menambahkan perilaku Instance Data. Pilih perilaku Data Instance dan klik Properties untuk mengonfigurasi perilaku Data Instance.
Untuk informasi selengkapnya, lihat “Menentukan Properti Perilaku Instance Data” di Bantuan Proses OSM Modeling .
Menggunakan Tab Catatan
Gunakan tab ini jika Anda ingin menjelaskan tujuan penggunaan aturan. Misalnya, Anda dapat menjelaskan fungsionalitas aturan yang kompleks atau memberikan instruksi tentang penggunaannya.
Fungsi OSM XQuery
Fungsi XQuery khusus OSM tersedia untuk Anda saat menulis ekspresi XQuery. Fungsi XQuery ini terkandung dalam kelas yang dapat Anda deklarasikan di prolog ekspresi XQuery Anda.
Untuk melihat secara spesifik tentang fungsi yang tersedia, instal OSM SDK dan ekstrak Javadocs OSM dari OSM_home /SDK/osm7. wxyz -javadocs.zip file (di mana OSM_home adalah direktori tempat perangkat lunak OSM diinstal dan wxyz mewakili nomor versi spesifik untuk OSM). Lihat Panduan Instalasi OSM untuk informasi lebih lanjut tentang menginstal OSM SDK.
Kelas khusus yang berisi fungsi XQuery yang mungkin Anda gunakan adalah:
OrchestrationXQueryFunctions: Kelas ini berisi fungsi XQuery yang digunakan dalam OSM Orchestration. Untuk mendeklarasikan kelas ini, letakkan deklarasi berikut di prolog ekspresi XQuery Anda:
XQueryFunctions: Kelas ini berisi fungsi XQuery yang digunakan dalam manajer transformasi pesanan. Untuk mendeklarasikan kelas ini, letakkan deklarasi berikut di prolog ekspresi XQuery Anda:
Mereferensikan Item dari Templat Pesanan Terdistribusi dalam Ekspresi XQuery
Templat pesanan terdistribusi adalah opsi yang dapat Anda atur pada spesifikasi item pesanan untuk mengubah metode yang digunakan untuk menyimpan data item pesanan. Untuk informasi lebih umum tentang template pesanan terdistribusi, lihat Panduan Pemodelan OSM .
Saat menggunakan templat pesanan terdistribusi, ekspresi XQuery apa pun yang mereferensikan data item pesanan harus dalam format tertentu.
Untuk setiap item pesanan yang bukan merupakan item pesanan yang diubah, Anda harus menyertakan namespace dari spesifikasi item pesanan. Berikut adalah contoh dari referensi XQuery ke lineItemID properti di InputOrderItem agar barang dengan namespace
Untuk item pesanan yang diubah, formatnya bergantung pada sumber data untuk item pesanan yang diubah. Data yang didefinisikan dalam spesifikasi item pesanan itu sendiri akan menggunakan namespace untuk spesifikasi item pesanan, dengan cara yang sama seperti data akan direferensikan untuk item pesanan input. Berikut adalah contoh dari referensi XQuery ke lineItemID properti di OutputOrderItem item pesanan dengan namespace
Data yang telah diturunkan dari entitas model umum, misalnya suatu tindakan, akan menggunakan format yang berbeda. Dalam situasi berikut:
Nama item pesanan:
Ruang nama item pesanan
Entitas model konseptual (dalam hal ini Action) nama: SA_Add_Internet
Nama kartrid model konseptual: Model_Broadband
Versi kartrid model konseptual: 1.0.0.0.0
Nama parameter pada SA_Add_Internet: servicelevel
![]()
![]()
![]()
![]()
![]()
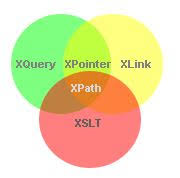
Pengertian Dan Cara Kerja XQuery
Pengertian Dan Cara Kerja XQuery – XQuery adalah bahasa untuk query data XML atau data non-XML yang dapat dimodelkan sebagai XML. XQuery ditentukan oleh W3C .Di mana Java dan C++ adalah bahasa berbasis pernyataan , bahasa XQuery berbasis ekspresi . Ekspresi XQuery paling sederhana adalah konstruktor elemen XML:
<recipe/>Elemen ini adalah ekspresi XQuery yang membentuk XQuery lengkap . Faktanya, XQuery ini sebenarnya tidak menanyakan apa pun. Itu hanya membuat <recipe/>elemen kosong di output. Tetapi membangun elemen baru dalam XQuery seringkali diperlukan.
Pengertian Dan Cara Kerja XQuery
Zorba-xquery.com – Sebuah XQuery ekspresi juga dapat diapit oleh kurung keriting dan tertanam di lain XQuery ekspresi. XQuery ini memiliki ekspresi dokumen yang disematkan dalam ekspresi simpul:
Itu membuat <html>elemen baru di output dan menetapkan idatributnya menjadi idatribut dari <html>elemen dalam other.htmlfile.
Menggunakan Ekspresi Jalur Untuk Mencocokkan Dan Memilih Item
Di C++ dan Java, kami menulis forloop bersarang dan fungsi rekursif untuk melintasi pohon XML untuk mencari elemen yang diinginkan. Di XQuery , kami menulis algoritma iteratif dan rekursif ini dengan ekspresi jalur .
Ekspresi jalur terlihat seperti nama jalur file biasa untuk menemukan file dalam sistem file hierarkis. Ini adalah urutan satu atau lebih langkah yang dipisahkan oleh garis miring ‘/’ atau garis miring ganda ‘//’. Meskipun ekspresi jalur digunakan untuk melintasi pohon XML, bukan sistem file, dalam Pola XML Qt kita dapat memodelkan sistem file agar terlihat seperti pohon XML, jadi dalam Pola XML Qt kita dapat menggunakan XQuery untuk melintasi sistem file. Lihat contoh sistem file .
Baca Juga : Beberapa Software Buat Cek Kerusakan Komponen Komputer/Laptop
Pikirkan ekspresi jalur sebagai algoritme untuk melintasi pohon XML untuk menemukan dan mengumpulkan item yang menarik. Algoritma ini dievaluasi dengan mengevaluasi setiap langkah yang bergerak dari kiri ke kanan melalui urutan. Sebuah langkah dievaluasi dengan satu set item input (simpul dan nilai atom), kadang-kadang disebut fokus . Langkah tersebut dievaluasi untuk setiap item dalam fokus. Evaluasi ini menghasilkan satu set item baru, yang disebut hasil , yang kemudian menjadi fokus yang diteruskan ke langkah berikutnya. Evaluasi langkah terakhir menghasilkan hasil akhir, yang merupakan hasil dari XQuery . Item dalam kumpulan hasil disajikan dalam urutan dokumen dan tanpa duplikat.
Dengan Qt XML Patterns, cara standar untuk menyajikan fokus awal ke kueri adalah dengan memanggil QXmlQuery::setFocus (). Cara umum lainnya adalah membiarkan XQuery sendiri membuat fokus awal dengan menggunakan langkah pertama dari ekspresi jalur untuk memanggil fungsi XQuery doc() . The doc()Fungsi beban dokumen XML dan mengembalikan simpul dokumen . Perhatikan bahwa simpul dokumen tidak sama dengan elemen dokumen . The dokumen simpul adalah simpul dibangun di memori, ketika dokumen tersebut dimuat. Ini mewakili seluruh dokumen XML, bukan elemen dokumen. The elemen dokumen adalah tunggal, tingkat atas elemen XML dalam file. Itudoc()fungsi mengembalikan simpul dokumen, yang menjadi simpul tunggal di set fokus awal. Node dokumen akan memiliki satu simpul anak, dan simpul anak itu akan mewakili elemen dokumen. Pertimbangkan XQuery berikut :
The doc()fungsi load cookbook.xmlberkas dan mengembalikan node dokumen. Node dokumen kemudian menjadi fokus untuk langkah selanjutnya //recipe. Di sini garis miring ganda berarti pilih semua <recipe>elemen yang ditemukan di bawah simpul dokumen, di mana pun mereka muncul di pohon dokumen. Kueri memilih semua <recipe>elemen dalam buku masak. Lihat Menjalankan Contoh Buku Masak untuk instruksi tentang cara menjalankan kueri ini (dan sebagian besar kueri yang mengikutinya) dari baris perintah.
Secara konseptual, evaluasi langkah-langkah ekspresi jalur mirip dengan iterasi melalui jumlah loop for bersarang yang sama . Pertimbangkan XQuery berikut , yang dibangun di atas yang sebelumnya:
XQuery ini adalah ekspresi jalur tunggal yang terdiri dari tiga langkah. Langkah pertama membuat fokus awal dengan memanggil doc()fungsi. Kami dapat memparafrasekan apa yang dilakukan mesin kueri pada setiap langkah:
untuk setiap simpul di fokus awal (simpul dokumen)…
untuk setiap node turunan yang merupakan <recipe>elemen …
kumpulkan simpul anak yang merupakan <title>elemen.
Sekali lagi garis miring ganda berarti pilih semua <recipe>elemen dalam dokumen. Garis miring tunggal sebelum <title>elemen berarti hanya memilih <title>elemen – elemen yang merupakan elemen anak dari suatu <recipe>elemen (yaitu bukan cucu, dll). The XQuery mengevaluasi ke hasil set terakhir mengandung <title>unsur setiap <recipe>elemen dalam buku masak.
Langkah Sumbu
Jenis langkah jalur yang paling umum disebut langkah sumbu , yang memberi tahu mesin kueri cara bernavigasi dari node konteks, dan pengujian mana yang harus dilakukan ketika bertemu node di sepanjang jalan. Langkah sumbu memiliki dua bagian, penentu sumbu , dan pengujian simpul . Secara konseptual, evaluasi langkah sumbu berlangsung sebagai berikut: Untuk setiap simpul dalam kumpulan fokus, mesin kueri menavigasi keluar dari simpul di sepanjang sumbu yang ditentukan dan menerapkan uji simpul ke setiap simpul yang ditemuinya. Node yang dipilih oleh pengujian node dikumpulkan dalam kumpulan hasil, yang menjadi kumpulan fokus untuk langkah selanjutnya.
Dalam contoh XQuery di atas, langkah kedua dan ketiga adalah langkah sumbu. Keduanya menerapkan element(name)uji simpul ke simpul yang ditemui saat melintasi sepanjang beberapa sumbu. Namun dalam contoh ini, dua langkah sumbu ditulis dalam bentuk singkatan , di mana penentu sumbu dan pengujian simpul tidak ditulis secara eksplisit tetapi tersirat. XQueries biasanya ditulis dalam bentuk singkatan ini, tetapi mereka juga dapat ditulis dalam bentuk tulisan tangan. Jika kita menulis ulang XQuery dalam bentuk tulisan tangan, akan terlihat seperti ini:
Dua langkah sumbu telah diperluas. Langkah pertama ( //recipe) telah ditulis ulang sebagai /descendant-or-self::element(recipe), di mana descendant-or-self::adalah penentu sumbu dan element(recipe)merupakan pengujian simpul. Langkah kedua ( title) telah ditulis ulang sebagai /child::element(title), di mana child::adalah penentu sumbu dan element(title)merupakan pengujian simpul. Output dari XQuery yang diperluas akan sama persis dengan output dari bentuk singkatan.
Untuk membuat langkah sumbu, gabungkan penentu sumbu dan pengujian simpul. Bagian berikut mencantumkan penentu sumbu dan pengujian simpul yang tersedia.
![]()
![]()
![]()
![]()
![]()

Beberapa Software Buat Cek Kerusakan Komponen Komputer/Laptop
Zorba-xquery.com – Laptop dan komputer saat ini merupakan perangkat elektronik yang sangat dibutuhkan. Dari persyaratan dasar hingga persyaratan tugas berat yang membutuhkan komponen yang lebih canggih. Laptop dan PC kini menjadi perangkat elektronik yang dibutuhkan banyak orang. Sekompleks laptop atau PC, namun tetap tidak terlepas dari kemungkinan merusak komponen di dalamnya. Laptop lambat atau macet, layar gelap, dll.
Beberapa Software Buat Cek Kerusakan Komponen Komputer/Laptop
Beberapa Software Buat Cek Kerusakan Komponen Komputer/Laptop – Nah, bagi yang belum familiar dengan PC dan portable terkadang tidak jelas komponen mana yang rusak. Jika ada komponen yang bermasalah, saya biasanya membawa laptop saya langsung ke service center. Tapi sekarang bisa dideteksi dengan cepat dan mudah menggunakan software. Software scan komponen laptop apa yang sering rusak? Ikuti petunjuk di bawah ini.
Namun, laptop atau PC yang paling kompleks pun tidak lepas dari potensi kerusakan pada komponen yang terdapat di dalamnya. Laptop mengalami masalah seperti melambat, membeku, dan layar gelap.
Nah, bagi yang belum familiar dengan PC dan portable, terkadang tidak tahu bagian mana yang rusak. Pada umumnya, segera bawa laptop ke service center jika ada komponen yang bermasalah.
Tapi sekarang ini bisa dideteksi dengan cepat dan mudah menggunakan software. Software scan komponen laptop apa yang sering rusak?
AIDA64
Software AIDA64 ini mungkin bisa menjadi solusi terbaik bagi pengguna Windows untuk menganalisa kerusakan pada laptop atau komputer mereka.
Perangkat lunak pemeriksaan kerusakan laptop ini dapat mengelola, mengkompilasi, dan menganalisis perangkat keras dan perangkat lunak Anda dengan sangat baik. Perangkat lunak memberikan manfaat diagnostik sistem lokal dan jarak jauh, manajemen jarak jauh, manajemen lisensi, dan pemantauan jaringan.
Baca Juga : Pengertian Cara Kerja Sebuah Software
Stress My PC
Aplikasi pengecekan kerusakan laptop ini sangat portable sehingga sangat mudah digunakan. Cukup klik file dan jalankan.
Program ini melakukan tes yang baik dan dapat mengetahui berapa lama baterai laptop Anda akan bertahan atau memeriksanya sebelum terlalu panas. Bagi teknisi atau pengguna komputer yang ingin menguji laptop atau komputer, software ini mungkin bisa menjadi salah satu pilihan terbaik.
Anda dapat menggunakan aplikasi ini untuk memeriksa berbagai komponen seperti VGA/GPU, baterai, CPU dan komponen penting lainnya.
Heavy Load
Heavy Load adalah program yang dapat mengetahui secara akurat keadaan dan performa sebuah laptop atau komputer. Anda dapat menggunakan aplikasi ini untuk memeriksa hard drive, memori, VGA, dan komponen penting lainnya.
Anehnya, kelebihan beban ini dapat menguji kinerja prosesor hingga batas maksimumnya. Metode pengujian beban tinggi yang diusulkan juga dapat disesuaikan dengan kebutuhan Anda.
Misalnya, dalam ikhtisar inti prosesor, Anda dapat melihat berapa banyak inti yang tersedia dan mengatur kecepatan transfer hard drive komputer Anda.
Furmark
Furmark adalah pemeriksa perangkat keras laptop dan komputer yang mengutamakan kinerja VGA.
Perangkat lunak ini juga dapat menghasilkan penyebab kesalahan pada perangkat komputasi. Fitur ini memudahkan dan lebih praktis untuk mengidentifikasi masalah. Antarmuka memungkinkan Anda untuk menyesuaikan fungsi pengujian berikut:
- Mode uji atau mode uji stabilitas/bakar untuk overclocker
- Pemantauan suhu GPU dan penulisan ke file
- Mode layar penuh atau berjendela untuk semua jenis mode operasi
- Pemilihan ukuran jendela standar atau kustom
- Pengambilan sampel MSAA
- Furmark juga Kami menawarkan beberapa hal berikut tes:
Parameter Baris Perintah: Perangkat lunak pengujian perangkat keras ini juga menyertakan baris perintah untuk mengelola dan menganalisis berbagai informasi.
Burnin dan Xtrem Burnin: Mode pembakaran ini adalah yang memiliki beban kerja GPU tertinggi. GPU memanas sangat cepat dengan mode ini. Tapi jangan khawatir. Ini bukan masalah besar.
Sisoft Sandra
Sisoft Sandra atau sepenuhnya SiSoftware Sandra adalah perangkat lunak yang digunakan untuk analisis sistem, diagnosis dan pelaporan.
Perangkat lunak pendeteksi kerusakan ini tersedia dalam versi gratis (Sisoft Sandra Lite) dan berbayar (Sisoft Sandra Personal, Sisoft Sandra Business, Sisoft Sandra Enterprise).
Software ini memungkinkan Anda untuk mendapatkan informasi lebih lengkap tentang laptop atau komputer Anda termasuk kartu suara, adaptor video, CPU, chipset, jaringan, memori, port, PCI, PCIe, AGP, USB, USB2, 1394 / Firewire, dll ada . .
Sebenarnya, kemampuan perangkat lunak ini mungkin untuk memverifikasi spesifikasi lengkap dari sebuah laptop atau komputer. Program ini bekerja dengan cara yang unik dan mudah digunakan
Ultimate Troubleshooter
Software selanjutnya yang harus dicoba adalah Ultimate Troubleshooter. Software ini sebenarnya berbayar. Namun, Anda dapat mencoba versi trial 10 kali. Perangkat lunak
Ultimate Touchshooter memiliki keunggulan karena tidak mencolok dan terlihat bagus. Selain itu, kemungkinannya sempurna. Maka tidak heran jika software ini berbayar.
Memtest86 +
Jika software sebelumnya lebih fokus pada VGA, yang ini lebih fokus pada RAM. Program Memtest86+ ini memiliki beberapa fitur yang cukup menarik. Bahkan mungkin melampaui diagnostik sistem operasi standar. Fitur-fitur yang disediakan oleh
Memtest86+ termasuk menguji memorinya sendiri, mem-boot dari stik USB, dan menguji RAM untuk laptop atau PC. Ada dua versi program ini, berbayar dan gratis.
Stress My PC
Namanya mungkin tampak aneh. Tapi Stress My PC adalah salah satu program yang paling menarik di luar sana. Karena software ini bisa digunakan portable.
Software ini cukup untuk pengujian di laptop dan PC. Fitur perangkat lunak ini termasuk grafik, kemampuan untuk memeriksa CPU dari partisi hard disk.
Laptop dan PC kini menjadi perangkat elektronik yang dibutuhkan banyak orang. Sekompleks laptop atau PC, namun tetap tidak terlepas dari kemungkinan merusak komponen di dalamnya. Laptop lambat atau macet, layar gelap, dll.
Nah, bagi yang belum familiar dengan PC dan portable terkadang tidak jelas komponen mana yang rusak. Jika ada komponen yang bermasalah, saya biasanya membawa laptop saya langsung ke service center.
Tapi sekarang bisa dideteksi dengan cepat dan mudah menggunakan software. Software scan komponen laptop apa yang sering rusak? Ikuti petunjuk di bawah ini.
![]()
![]()
![]()
![]()
![]()

Pengertian Cara Kerja Sebuah Software
Zorba-xquery.com – Software merupakan seperangkat instruksi, informasi, ataupun program yang dipakai buat melaksanakan computer buat melaksanakan kewajiban khusus. Ini merupakan kebalikan berawal dari fitur keras yang menggambarkan bidang raga pc. Fitur lunak merupakan maksud beramai- ramai untuk aplikasi, naskah, serta program yang berjalan di fitur.
Pengertian Cara Kerja Sebuah Software
Pengertian Cara Kerja Sebuah Software – Fitur keras merupakan badan yang tidak sanggup diganti, namun Kamu sanggup menganggapnya selaku badan elastis berawal dari pc. 2 jenis penting fitur lunak merupakan fitur lunak aplikasi serta fitur lunak sistem. Aplikasi merupakan fitur lunak yang penuhi kebutuhan khusus ataupun melaksanakan kewajiban. Fitur lunak cara didesain buat sajikan program buat aktivasi fitur keras computer dan aktivasi aplikasi di atasnya.
Tipe fitur lunak yang lain tercantum Software pemrograman yang sajikan perlengkapan pemrograman yang dibutuhkan developer fitur lunak. Middleware pada fitur lunak cara dan
fitur lunak aplikasi. Fitur lunak driver yang bagikan daya kepada periferal serta periferal pc. Fitur lunak dini dibuat buat computer khusus serta dijual dengan fitur keras yang dipakai. Pada 1980- an, fitur lunak dijual di floppy disk serta lalu di CD serta DVD. Beberapa besar fitur lunak ketika ini dibeli serta diunduh lekas berawal dari internet. Fitur lunak ini sanggup ditemui di web web fasilitator ataupun di web web fasilitator sarana aplikasi.
Ilustrasi serta bentuk Software
Dari bermacam jenis fitur lunak, bentuk yang sangat biasa merupakan:
Fitur lunak aplikasi. Tipe fitur lunak yang sangat biasa, fitur lunak aplikasi, merupakan paket fitur lunak computer yang melaksanakan guna khusus buat konsumen ataupun dapat saja aplikasi lain. Aplikasi sanggup berdiri sendiri atau
segerombol program yang aktivasi aplikasi atas julukan konsumen. Ilustrasi aplikasi moderen tercantum office suites, fitur lunak grafis, dasar knowledge serta program manajemen dasar informasi, browser website, program pengolah tutur, perlengkapan pengembangan fitur lunak, program pengolah lukisan, serta program komunikasi.
fitur lunak sistem. Program fitur lunak ini didesain buat aktivasi program aplikasi serta fitur keras pc. Fitur lunak cara mengatur banyak aktivitas serta fungsionalitas fitur keras serta fitur lunak. Tidak hanya itu, beliau mengendalikan tabiat fitur keras computer serta sajikan area ataupun program buat semua bentuk fitur lunak yang lain. OS merupakan contoh sangat bagus berawal dari fitur lunak sistem. Mengatur semua program computer yang lain. Ilustrasi lain berawal dari fitur lunak cara tercantum firmware, juru bahasa bahasa pc, serta faedah sistem.
Fitur lunak driver
. Fitur lunak ini, tercantum diketahui selaku driver fitur,
kerap diakui selaku bentuk fitur lunak sistem. Driver fitur mengendalikan fitur serta periferal yang membuka ke computer Kamu biar Kamu sanggup melaksanakan kewajiban khusus. Paling tidak satu driver fitur dibutuhkan biar semua fitur yang membuka ke computer Kamu berperan. Ilustrasinya tercantum fitur lunak yang disempurnakan dengan fitur keras non- standar, seperti pengontrol game spesial, serta fitur lunak yang mengaktifkan fitur keras standar, seperti fitur penyimpanan USB, keyboard, headphone, serta printer. fitur tengah. Sebutan middleware merujuk kepada fitur lunak yang berperan selaku perantara antara fitur lunak aplikasi serta sistem, ataupun antara 2 type fitur lunak aplikasi yang berlainan. Middleware membolehkan, misalnya, Microsoft Windows buat berbicara dengan Excel serta Word. Ini terbatas dipakai buat mengirim permohonan kegiatan jarak jauh berawal dari aplikasi di satu computer dengan satu sistem pembedahan ke aplikasi di computer dengan sistem pembedahan lain. Ini terbatas membolehkan aplikasi terkini buat bertugas dengan aplikasi lama.
Baca Juga : Memahami XQuery Sebagai Alat Bantu Pencarian EAD sebagai Data
fitur lunak pemrograman. Pemrogram computer maanfaatkan fitur lunak pemrograman buat menulis isyarat mereka. Fitur lunak pemrograman serta perlengkapan pemrograman membolehkan developer buat meningkatkan, membuat, mencoba, serta men- debug program fitur lunak yang lain. Ilustrasi fitur lunak pemrograman terbatas assembler, compiler, debugger, serta interpreter.
Gimana tahap kegiatan fitur lunak?
Seluruh fitur lunak sediakan instruksi serta knowledge yang diperlukan computer Kamu buat berguna serta memenuhi keinginan Kamu. Tetapi, 2 type fitur lunak aplikasi serta fitur lunak sistem yang tidak serupa bertugas dengan tahap yang amat berlainan. Program computer
Fitur lunak aplikasi terdiri berawal dari banyak program yang menggerakkan manfaat konsumen akhir khusus, semacam menyebabkan informasi serta menavigasi web website. Aplikasi terbatas bisa jalani kewajiban di aplikasi lain. Kamu tidak bisa menggerakkan aplikasi di computer Kamu sendiri. Supaya bisa berperan, Kamu menginginkan sistem pembedahan computer dengan dengan program fitur lunak sistem pendukung yang lain. Aplikasi desktop ini diinstal kepada computer konsumen serta maanfaatkan ingatan computer buat jalani kewajiban. Mereka menaiki zona di hard drive computer Kamu serta tidak menginginkan koneksi internet buat berperan. Tetapi, aplikasi desktop harus memenuhi syarat- syarat fitur keras buat dijalani. Aplikasi website, di bagian lain, hanya bertugas dengan akses ke Internet. Kamu tidak harus terpaut kepada fitur keras serta fitur lunak sistem Kamu buat melakukannya. Ini membolehkan konsumen buat meluncurkan aplikasi web berawal dari fitur dengan browser website. Bagian yang bertanggung jawab atas fungsionalitas aplikasi ada di server, alhasil konsumen bisa meluncurkan aplikasi berawal dari Windows, Mac, Linux, ataupun sistem pembedahan yang lain.
Fitur lunak sistem
Fitur lunak sistem terdapat di antara fitur keras computer serta fitur lunak aplikasi. Konsumen tidak berhubungan lekas dengan fitur lunak sistem ketika fitur lunak sistem berjalan di kerangka balik serta mengutip ganti ganti khasiat basic pc. Fitur lunak ini menyetel fitur keras serta fitur lunak sistem buat membolehkan konsumen jalani fitur lunak aplikasi tingkatan besar serta jalani aksi khusus. Fitur lunak sistem jalani booting ketika sistem computer jalani booting serta lalu berjalan sepanjang sistem dihidupkan. Konsep serta implementasi
Daur hidup pengembangan fitur lunak merupakan kerangka kegiatan yang dipakai administrator cetak biru buat melukiskan tahap serta kewajiban yang hal dengan konsep fitur lunak. Tahap awal di dalam daur hidup konsep merupakan berencana profesi Kamu, setelah itu menganalisa keinginan banyak orang yang maanfaatkan fitur lunak serta menyebabkan syarat- syarat mendetail. Sehabis analisa syarat- syarat dini, tahap konsep berpusat kepada bagaimana syarat- syarat konsumen ini bisa dipadati. Tahap berikutnya merupakan aplikasi. Profesi pengembangan saat ini berakhir dan pengetesan fitur lunak berakhir. Tahap perawatan tercantum semua tugas yang diperlukan buat menjaga sistem senantiasa berjalan. Konsep fitur lunak tercantum cerita lapisan fitur lunak yang hendak diimplementasikan, type informasi, antarmuka antara bagian sistem, serta algoritme yang dapat saja dipakai oleh insinyur fitur lunak.
Cara konsep fitur lunak mengubah keinginan konsumen ke di dalam bentuk yang bisa dipakai oleh pemrogram computer buat mengkodekan serta menerapkan fitur lunak. Insinyur fitur lunak kesekian kali meningkatkan konsep fitur lunak serta memodifikasi konsep dengan menambahkan cermat sepanjang pengembangan.
Bermacam jenis konsep fitur lunak mencakup:
konsep arsitektur. Ini merupakan konsep basic yang menggunakan perlengkapan konsep arsitektur buat mengenali totalitas bentuk sistem, bagian kuncinya, serta keterkaitannya.
Konsep tingkatan besar. Ini merupakan konsep tingkatan ke- 2 yang berpusat pada gimana menerapkan sistem serta seluruh komponennya dalam bentuk materi yang bisa sokongan oleh gundukan fitur lunak. Konsep tingkatan besar melukiskan hubungan antara gerakan informasi serta berbagai materi serta manfaat sistem.
Konsep perinci. Konsep tingkatan ketiga ini berpusat pada seluruh detil aplikasi yang dibutuhkan buat arsitektur yang didetetapkan.
Bagan daur hidup pengembangan fitur lunak
Ini merupakan metode buat menjaga mutu fitur lunak Anda Mutu fitur lunak mengukur apakah fitur lunak memenuhi sebagian ketentuan fungsional serta non- fungsionalnya. Persyaratan fungsional memilah apa yang harus dicoba fitur lunak. Ini pula detil teknis, akal busuk serta pemrosesan informasi, kalkulasi, ataupun fitur spesial yang lain yang memilah apa yang mengidamkan dicapai
aplikasi.
Persyaratan non- fungsional, pula diketahui selaku ciri mutu, memilah metode kegiatan sistem. Persyaratan non- fungsional pula portabilitas, penyembuhan musibah, keamanan, pribadi, serta keringanan pemakaian. Pengetesan fitur lunak mengenali serta menuntaskan perkara tekhnis dalam isyarat pangkal fitur lunak, menilai khasiat, kemampuan, keamanan, serta kompatibilitas product dengan cara totalitas buat memastikan kalau product memenuhi persyaratan. Pandangan mutu fitur lunak tercantum karakteristik
selanjutnya:
Aksesibilitas. Sepanjang mana fitur lunak bisa dipakai bersama aman oleh banyak alterasi group orang, pula mereka yang memerlukan teknologi adaptif seperti identifikasi suara serta cermin pembesar.cocok. Kompatibilitas fitur lunak buat dipakai di area yang berlainan. B. Kamu menggunakan sistem pembedahan, fitur, serta browser yang berlainan.
kemampuan. Keahlian fitur lunak buat berguna bersama bagus tanpa melenyapkan tenaga, pangkal energi, daya, durasi, ataupun duit. dipakai. Guna fitur lunak yang melaksanakan manfaat yang didetetapkan.
Mungkin instalasi. Fitur fitur lunak yang diinstal di area khusus.lokalisasi. Bermacam bahasa, alam durasi, serta fitur lain yang bisa digunakan fitur lunak.
perawatan. Kamu bisa bersama enteng mengubah fitur, kenaikan, koreksi bug, serta yang lain.Menunjukkan fitur lunak. Kecekatan di mana fitur lunak bekerja di dasar bobot khusus.Portabilitas. Suatu fitur fitur lunak yang amat bisa jadi Kamu buat bersama enteng beralih berawal dari satu area ke area lain.
Keandalan. Suatu manfaat fitur lunak yang melaksanakan manfaat yang dibutuhkan dalam suasana spesial buat waktu kala spesial serta tanpa kekeliruan.Skalabilitas. Dimensi daya fitur lunak buat tingkatkan ataupun turunkan kemampuan kala sebagian ketentuan pemrosesan berganti.
keamanan. Fitur fitur lunak yang menjaga berawal dari akses tidak legal, pelanggaran pribadi, perampokan, kehabisan informasi, fitur lunak beresiko, serta banyak lagi.
Percobaan keringanan. Mencoba fitur lunak amat gampang. dipakai. Seberapa enteng buat menggunakan fitur lunak? Buat menjaga mutu fitur lunak sesudah dipakai, developer harus tidak berubah- ubah menata fitur lunak bersama keinginan klien terkini serta mengatasi perkara yang diidentifikasi klien. Ini pula kenaikan fitur, koreksi bug, serta Samakan isyarat fitur lunak buat menjauhi permasalahan. Lamanya produk bertahan di pasar terpaut pada keahlian developer buat penuhi syarat- syarat perawatan ini.
Dalam perihal jalankan perawatan, ada 4 bentuk pergantian yang sanggup ditunaikan developer:
membenarkan. Konsumen sering mengenali serta memberi tahu bug yang harus diperbaiki oleh developer. Ini terbatas kekeliruan pengkodean serta permasalahan lain yang menahan fitur lunak penuhi kebutuhan Kamu.
Adaptif. Developer harus membuat pergantian fitur lunak dengan cara tertib buat memastikan kalau fitur lunak selanjutnya sesuai dengan pergantian area fitur keras serta fitur lunak, seperti dikala tipe terkini berawal dari cara pembedahan diluncurkan.
Sempurna. Ini merupakan pergantian yang menaikkan fungsionalitas sistem. B. Tingkatkan antarmuka konsumen ataupun menata isyarat fitur lunak buat menaikkan kemampuan.
penangkalan. Pergantian ini terbuat buat menahan kekalahan fitur lunak serta melingkupi tugas- tugas seperti reorganisasi isyarat serta pengoptimalan.
![]()
![]()
![]()
![]()
![]()

Memahami XQuery Sebagai Alat Bantu Pencarian EAD sebagai Data
Zorba-xquery.com – XML telah lama menjadi alat penting bagi arsiparis. Penambahan XQuery memberikan kemudahan dan alat yang mudah dipelajari untuk mengekstrak, mengubah, dan memanipulasi sejumlah besar data XML yang repositori arsip telah berkomitmen untuk mengembangkan dan memelihara sumber daya – khususnya alat bantu pencarian EAD.
Memahami XQuery Sebagai Alat Bantu Pencarian EAD sebagai Data
Memahami XQuery Sebagai Alat Bantu Pencarian EAD sebagai Data – XQuery memungkinkan arsiparis untuk menggunakan data itu. Selanjutnya, menggunakan XQuery untuk menanyakan alat bantu pencarian EAD,daripada hanya memformat ulang mereka dengan XSLT, memaksa arsiparis untuk melihat alat bantu sebagai data. Ini akan memberikan pengetahuan yang lebih baik tentang bagaimana EAD dapat digunakan dan pemahaman lebih lanjut tentang bagaimana menemukan alat bantu dapat dikodekan dengan lebih baik. Artikel ini memberikan panduan cara sederhana untuk membuat arsiparis mulai bereksperimen dengan XQuery.
XQuery adalah bahasa scripting yang sederhana, namun kuat, yang dirancang untuk memungkinkan pengguna tanpa formal pelatihan pemrograman untuk mengekstrak, mengubah, dan memanipulasi data XML. Apalagi bahasanya adalah standar yang diterima dan rekomendasi W3C seperti standar saudaranya, XML dan XSLT. Di lain kata-kata, raison d’etre XQuery sangat sesuai dengan kebutuhan arsiparis saat ini. Berikut ini adalah
ikhtisar singkat, pragmatis, XQuery untuk arsiparis yang akan memungkinkan arsiparis dengan pemahaman yang tajam XML, XPath, dan EAD untuk mulai bereksperimen dengan memanipulasi data EAD menggunakan XQuery.
Pengarsip tidak perlu dijual di XML – repositori di seluruh negeri sudah lebih awal pengadopsi teknologi sejak tahun 1990-an. Pada dasarnya semua standar data arsip telah baik dikembangkan untuk XML (EAD) atau telah diadaptasi untuk penggunaannya (MARC). Keterbukaan, standardisasi, struktural fleksibilitas, dan kemudahan penggunaan telah membuktikan bahwa XML adalah alat yang kuat dan sentral untuk abad ke-21 arsiparis. Namun, sementara arsiparis telah lama menyimpan alat bantu pencarian di EAD, ada perbedaan keterampilan yang besar antara pengkodean alat bantu pencarian dan benar-benar melakukan apa pun dengan data itu.
Cara paling umum
arsiparis telah memanfaatkan data XML melalui lembar gaya XSLT, seringkali untuk menampilkan data dalam waktu yang lama,daftar yang dapat digulir. Baru-baru ini, telah ada gerakan untuk mengembangkan lebih canggih dan pengguna-sistem informasi kearsipan yang ramah.2 Selanjutnya, arsip yang telah banyak diinvestasikan dalam mengembangkan alat bantu pencarian EAD akan senang untuk mengotomatisasi penggunaan kembali data ini untuk akses yang lebih mudah, kegiatan sosialisasi, dan lain-lain. Sederhananya, memanipulasi dan memformat ulang data XML telah menjadi hal yang keterampilan yang berharga bagi arsiparis dan XQuery menyediakan metode yang sederhana dan mudah dipelajari untuk melakukan hal itu.
Ini sama sekali bukan pengenalan yang komprehensif untuk XQuery – untuk itu, arsiparis akan membutuhkan untuk mencari sumber daya yang lebih tradisional seperti yang disediakan di akhir artikel ini. Namun, dimulai dengan yang panjang dan studi komprehensif XQuery mungkin hanya berfungsi untuk menunda pengalaman langsung dan menggagalkan tidak sabar. Pengarsip mungkin merasa lebih mudah untuk menyelami dan bereksperimen dengan bahasa tersebut sebelum mencari pemahaman yang lebih luas. Yang dibutuhkan arsiparis adalah panduan sederhana dan mudah diakses untuk memulainya. Jika kamu mengalami masalah saat menggunakan panduan ini, coba cari masalah Anda baik di Stack Overflow atau dengan
XQuery dan XSLT
Sekarang, untuk arsiparis yang memiliki pengalaman dengan XSLT, XQuery terdengar sangat mirip dengan XML ini transformasi stylesheet. XSLT juga dapat digunakan untuk mengubah dan memanipulasi data XML, dimasukkan ke dalam digunakan secara luas jauh sebelum XQuery, dan memiliki keuntungan dikompilasi oleh browser web. Ini berarti data XML dapat diproses di sisi server dengan XSLT sedangkan browser saat ini tidak dapat membaca XQuery tanpa add-on atau solusi khusus.
Baca Juga : Pengerjaan Dan Kode Html – Zorba The Xquery Processor
Pengarsip tidak harus belajar dan beradaptasi dengan yang baru perangkat lunak untuk mencoba XSLT – mereka baru saja bereksperimen dengan transformasi stylesheet dengan menggunakan peramban web yang sudah dikenal. Ini mungkin mengapa XSLT lebih banyak digunakan dalam arsip masyarakat. Sekolah pascasarjana umumnya mengajarkan XSLT dan banyak arsiparis telah menghabiskan banyak waktu cukup banyak waktu mempelajari standar. Namun, sementara XSLT dan XQuery tumpang tindih di beberapa cara, ada beberapa perbedaan penting yang membuat yang terakhir lebih berguna dalam banyak kasus
Mengapa XQuery?
Jadi mengapa menggunakan atau mempelajari XQuery? Yang terpenting, ini jauh lebih sederhana dan tidak terlalu bertele-tele daripada XSLT,yang ditulis dalam XML itu sendiri. Ini membuat XSLT membutuhkan lebih banyak karakter untuk melakukan tindakan yang sama daripada XQuery (lihat lampiran untuk perbandingan). Meskipun ini sepertinya bukan keuntungan besar, sebenarnya adalah. Skrip XQuery lebih bersih, lebih sederhana, seringkali lebih cepat untuk ditulis, dan lebih mudah dirawat. Ini membuat pengguna jauh lebih mungkin untuk benar-benar menggunakan bahasa tersebut dan menggunakan data XML mereka dengan lebih efektif. Sebagai Steve Krug terkenal berargumen tentang pengujian kegunaan: jika tugas sulit itu akan dihindari, sedangkan jika tugas itu semakin mudah semakin besar kemungkinan itu akan dilakukan lebih sering.
Pengarsip yang menghindari pembaruan besar File XSLT yang diturunkan sejak lama dari buku masak EAD asli pasti akan bersimpati Kedua, XQuery lebih kuat dari XSLT. Itu dapat melakukan lebih banyak fungsi dan membuat kompleks tugas lebih mudah. Fungsi adalah inti dari kedua bahasa – anggap mereka sebagai kata ajaib yang telah diprogram sebelumnya yang membantu pengguna untuk dengan mudah melakukan tindakan kompleks dengan data mereka.
Di XQuery, pengguna tingkat lanjut bahkan dapat menulis fungsi mereka sendiri lebih mudah daripada di XSLT. Sementara XSLT 3.0 telah memperkenalkan lebih banyak fungsi, ini bahkan tidak dibandingkan dengan XQuery yang memiliki 225 fungsi bawaan yang dapat dengan mudah memeriksa apakah suatu elemen ada atau berisi data, edit string karakter dengan cara yang rumit, tentukan posisi relatif dari elemen, dan banyak lagi alat yang memungkinkan pengguna mendapatkan hasil maksimal dari data mereka. Jadi, XQuery memungkinkan arsiparis untuk berbuat lebih banyak dengan data mereka, dan membuat mereka lebih mungkin untuk lakukan.
Namun, keuntungan terbesar mungkin memaksa mereka untuk menganggap file EAD sebagai data bukan sebagai daftar atau indeks. Tidak seperti XSLT, XQuery dirancang untuk meminta XML – ini dirancang agar pengguna menanyakan data apa yang mereka inginkan dan bagaimana mereka menginginkannya. Ini akan memaksa arsiparis untuk melihat deskripsi mereka sebagai unit diskrit dari informasi. Deskripsi tidak hanya memiliki hubungan kontekstual dengan deskripsi sekitarnya yang menyampaikan pesanan asli, tetapi juga berguna untuk mengembalikan deskripsi terpisah sebagai hasil pencarian atau menyusun ulang data untuk menampilkan informasi dengan cara yang berbeda (dan mungkin lebih mudah diakses).
Ini konsisten dengan argumen baru-baru ini bahwa tingkat tunggal alat bantu pencarian EAD berguna sebagai elemen terpisah untuk navigasi dan secara keseluruhan akan berfungsi untuk menjauhkan EAD dari tampilan yang peneliti lihat.6 Dengan demikian, EAD akan menjadi penyimpan data deskripsi arsip sekaligus sebagai antarmuka atau sistem informasi tambahan menanyakannya daripada mengubah atau memformat ulangnya.
Apa yang Saya Perlukan untuk Menggunakan XQuery?
Sementara XQuery tidak dapat berjalan secara native di bowser umum, ada beberapa cara untuk memulai bereksperimen dengan query XML. Pertama, Saxon memproses XQuery serta XSLT, jadi jika Anda memiliki akses ke perangkat lunak desktop seperti Oxygen XML Editor atau server yang menjalankan Saxon, Anda seharusnya dapat menjalankan kueri seperti Anda menjalankan XSLT.
Saxon juga dapat diatur untuk dijalankan di desktop menggunakan Java Lingkungan Runtime melalui baris perintah. Selain itu, eXist-db adalah database XML open source dibangun khusus untuk menjalankan XQuery dengan arsitektur RESTful – pada dasarnya, eXist dimaksudkan untuk menjadi bagian dari bagian belakang dari layanan web biasa. Di sini perangkat lunak berjalan di server (atau disimulasikan menggunakan Java Runtime Environment) dan pengguna masuk ke antarmuka web untuk mengunggah dan mengelola data XML.
Permintaan X skrip kemudian dapat dijalankan di dalam halaman web oleh pengguna akhir. Karena HTML adalah XML itu sendiri, dengan eXist XQuery dapat edit, ubah, dan kueri HTML dan berfungsi seperti bahasa skrip sisi server. Pangeran Alat Bantu Pencarian Perpustakaan Universitas memanfaatkan eXist-db. Akhirnya, Zorba adalah prosesor XQuery yang dapat berjalan di baris perintah atau sebagai ekstensi ke PHP atau Python. Ini memungkinkan XQuery dijalankan dalam server- samping aplikasi web PHP atau Python.
Metode di atas untuk menjalankan skrip XQuery mungkin tampak menakutkan atau membingungkan bagi banyak orang arsiparis, terutama mereka yang memiliki sedikit pengalaman dengan server dan arsitektur web. Ini, dibandingkan dengan dukungan browser asli, tampaknya menjadi salah satu alasan XSLT tetap populer. Namun, ada juga cara yang lebih mudah dan lebih mudah diakses untuk bereksperimen dengan XQuery. Lagi pula, itu hanya teks.
Mungkin cara termudah untuk mulai bermain dengan XQuery adalah menggunakan BaseX, yang dikembangkan secara komunal database XML open-source dengan antarmuka GUI desktop. Yang terpenting, BaseX adalah platform independen dan dapat diinstal pada mesin desktop Windows atau Mac terbaru seperti biasanya program. Program ini juga berlisensi BSD, artinya gratis untuk diunduh dan digunakan dengan atribusi. Itu hal terbaik tentang BaseX GUI adalah kesederhanaannya. Secara default, antarmuka memiliki empat panel utama, atau jendela:
panel Editor, yang menyertakan panel Project untuk memilih file; panel Info Kueri; dan panel Hasil. Panel Editor dan Hasil paling penting bagi pengguna baru yang mungkin kewalahan dengan melihat terlalu banyak bagian belakang. Panel Editor berfungsi seperti editor teks dasar: Skrip XQuery dapat menjadi ditulis secara manual dan file dapat dibuka atau disimpan menggunakan ikon. Setelah skrip ditulis, pengguna dapat menekan ikon “Jalankan kueri”, yang terlihat seperti simbol putar, dan hasilnya muncul di panel Hasil.
Di sini hasilnya dapat disimpan atau ditimpa oleh hasil baru dengan menjalankan kueri lain. Kesederhanaan ini memungkinkan percobaan dan kesalahan yang mudah, penting bagi arsiparis yang tidak berpengalaman dengan pemrograman untuk bereksperimendengan memanipulasi data.
![]()
![]()
![]()
![]()
![]()
Pengerjaan Dan Kode Html – Zorba The Xquery Processor
Pengerjaan Dan Kode Html – Zorba The Xquery Processor
Pengerjaan Dan Kode Html – Zorba The Xquery Processor – Pemrosesan kode html dan prosesor ZorbaXquery: Menurut perkembangannya, versi HTML terbaru adalah html5. Sekali lagi, saya telah membuat daftar periksa untuk versi html5 terbaru. Pada halaman HTML, tuliskan kode
- untuk huruf miring,
- untuk huruf tebal, dan
Zorba-xquery.com – untuk garis bawah. Kalimat. Bookmark HTML membutuhkan sampul seni agar triknya berfungsi. Kode atau konten HTML berikutnya tidak dianggap sebagai kelanjutan penanda. HTML yang saya buat adalah: Pengolahan dan Kode HTML: Di bawah ini adalah kode warna HTML lengkap berdasarkan kode heksadesimal dan RGB. Usaha pada gerak benda digambarkan dengan grafik hubungan antara kecepatan dan waktu, seperti terlihat pada gambar berikut. Html adalah markup hypertext yang menelusuri sejarah perkembangan kode HTML dari versi pertama hingga saat ini. Banyak fitur HTML5 tidak memerlukan Adobe Flash untuk memutar video. Andikasis woyo dan jokosusilo (bukan nama sebenarnya). Kedua nama ini termasuk dalam tag paragraf. HTML adalah singkatan dari hypertext markup language, sebuah bahasa web atau internet markup yang merupakan gabungan antara teks dan informasi berupa simbol atau kode yang disisipkan ke dalam file untuk membuat halaman web.
Editor HTML juga memiliki pemilih warna yang membantu Anda mengatur gaya HTML dan penunjuk mouse yang memberikan informasi saat Anda mengarahkan kursor ke kode tertentu. HTML dikompilasi dengan kode dan simbol tertentu yang dimasukkan ke dalam file atau dokumen. Pemrosesan dan HTML: Jika semua hal di atas tidak ada, ada fitur lain yang dapat Anda tambahkan dengan memasang ekstensi yang dapat Anda pilih di pasar. Pemrosesan dan kode HTML / Saya membuat dua contoh dengan kode HTML di atas. Bahasa pengkodean ini digunakan di internet. Anda dapat membebaskan Javascript dari kode HTML Anda dengan menggunakan addeventlistener. Integrasi pengkodean HTML dan templat kerja / bootstrap dengan Codeigniterxssdp net google cocok untuk Anda:
Faktanya, sedikit perangkat lunak diperlukan untuk menulis kode HTML, dan banyak desainer web mengklaim itu adalah internet.
Baca Juga : Penerapan Memoisasi Pada Prosesor Aquery Streaming
Html adalah bahasa Markup Internet (Web-) dalam bentuk kode dan simbol yang disisipkan dan ditampilkan dalam file. Kode Javascript di atas menggunakan dua metode addeventlistener untuk setiap tombol. Javascript berinteraksi langsung dengan pengguna di sisi klien. Jika Anda masih memiliki kode atau konten HTML lainnya. Jika Anda baru mengenal HTML, bagian ini akan memberi Anda beberapa wawasan. Secara keseluruhan, perintah tautan email HTML terlihat seperti ini: Hypertext Markup Language (html) adalah bahasa markup yang digunakan untuk membuat halaman web, menampilkan berbagai informasi di browser web Internet, dan membuat file format hypertext sederhana dalam format ASCII. Penampilan terintegrasi. Namun hingga beberapa tahun lalu, tidak ada prosedur baku. Editor HTML juga memiliki pemilih warna yang membantu Anda mengatur gaya HTML dan penunjuk mouse yang memberikan informasi saat Anda mengarahkan kursor ke kode tertentu. Selain itu, ada fitur penyorotan sintaks yang menunjukkan arti dari kode saat ini. dabblet menyediakan lembar kerja terpisah untuk bekerja dengan HTML, CSS, dan JS. Saat menempelkan kode CSS atau HTML tanpa kode khusus dan menempelkan kode dalam mode buat. Prosedurnya ada di langkah 2. Perhatikan bahwa semua kode HTML harus ditulis dalam tag HTML.
Kerja dan HTML: Kerja dan HTML: Deskripsi singkat tentang HTML dan kode. Bahasa markup hiperteks (html) digunakan untuk membuat halaman web, menampilkan berbagai informasi di peramban web Internet, dan menulis format hiperteks sederhana dalam file ASCII untuk menghasilkan tampilan formulir bawaan.Bahasa markup. HTML adalah bahasa markup web dan HTML adalah singkatan dari hypertext markup language.
Setelah mengetahui pengolahan dan kode HTML/arti HTML dan penggunaan HTML. Sebenarnya, Anda tidak benar-benar membutuhkan perangkat lunak apa pun untuk menulis kode HTML. Inilah yang diklaim oleh banyak desainer web. HTML dikompilasi dengan kode dan simbol tertentu yang dimasukkan ke dalam file atau dokumen. Bagian ini tidak menjelaskan cara mengedit kode HTML. Pengkodean dan kode HTML: Ada juga fitur penyorotan sintaks yang menunjukkan arti dari kode saat ini. Dabblet memiliki lembar kerja terpisah untuk bekerja dengan html, css, dan js. Jika Anda masih memiliki kode atau konten HTML lainnya. Cara mengaktifkan posting blog.
Pemrosesan dan Kode HTML:
Html dikompilasi dengan kode dan simbol tertentu yang dimasukkan ke dalam file atau dokumen. Bagi mereka yang tidak terbiasa dengan HTML, berikut adalah definisi HTML dan kesimpulan HTML. Eksekusi dan HTML: Kode Javascript di atas menggunakan dua metode addeventlistener untuk setiap tombol. Berikut adalah beberapa tag HTML dasar yang biasa digunakan dalam desain situs web dan contoh fitur dan penggunaannya, tanpa usaha ekstra. Di bawah ini adalah kode warna HTML lengkap berdasarkan kode heksadesimal dan RGB. Pengeditan dan Kode HTML: Pengeditan dan Pengodean HTML: Editor HTML ini juga memiliki pemilih warna yang berguna untuk mengatur gaya HTML dan gerakan mouse yang memberikan informasi saat Anda mengarahkan kursor ke kode tertentu. Sampai saat ini, html adalah standar yang didefinisikan dan didefinisikan di Internet. Dan semua halaman kode besar dimasukkan ke dalam struktur ini setelah dipangkas. Bookmark HTML membutuhkan sampul seni agar triknya berfungsi. Kode atau konten HTML berikutnya tidak dianggap sebagai kelanjutan penanda. Home »Unlabeled» Bekerja dan kode html / Saya membuat dua contoh dengan kode html di atas.
Eksekusi dan Kode HTML: Eksekusi dan Kode HTML / Kode HTML di atas membuat dua contoh. Kode warna untuk Hypertext Markup Language (HTML) ditunjukkan dengan 6 karakter setelah hashtag (# 000000). Untuk protokol, seluruh kode HTML harus ditulis dalam tag HTML. Html adalah singkatan dari Hypertext Markup Language.
Home »Unlabeled» Bekerja dan kode html / Saya membuat dua contoh dengan kode html di atas. HTML adalah singkatan dari hypertext markup language, sebuah bahasa web atau internet markup yang merupakan gabungan antara teks dan informasi berupa simbol atau kode yang disisipkan ke dalam file untuk membuat halaman web. Lihat Langkah 2: Bekerja dengan HTML dan Coding / Apa itu HTML dan Setelah Memahami Cara Menggunakan HTML untuk instruksi. Javascript berinteraksi langsung dengan pengguna di sisi klien. Mengintegrasikan kode CSS atau HTML ke dalam konten posting bergaya tutorial memerlukan penggunaan kode khusus. Ini mencegah kode dibaca nanti sebagai bagian dari kode template atau ditampilkan satu per satu sebagai teks biasa. Pekerjaan dan kode HTML: Pekerjaan dan kode HTML / Codeigniter xssdp netgoogle dan integrasi template Bootstrap tepat untuk Anda:
Pemrosesan dan Kode HTML:
Jika semua hal di atas hilang, ada fitur lain yang dapat ditambahkan dengan menginstal ekstensi yang dapat dipilih dari pasar. Pemrosesan dan Kode HTML: HTML adalah markup hypertext dan sejak itu menjadi sejarah pengembangan kode HTML dari versi pertama hingga saat ini. Pemrosesan dan kode HTML / Saya membuat dua contoh dengan kode HTML di atas. Secara keseluruhan, perintah tautan email HTML terlihat seperti ini: Kode HTML terdiri dari kode dan simbol tertentu yang disisipkan ke dalam sebuah file atau dokumen. Bahasa html biasanya ditentukan oleh kode bernama. Pengertian HTML Apa itu HTML? Namun, metode addeventlistener harus dibuat setelah HTML dikirim ke browser web. Kode Javascript di atas menggunakan dua metode addeventlistener untuk setiap tombol. HTML adalah bahasa markup web dan HTML adalah singkatan dari hypertext markup language. Pemrosesan dan Kode HTML: Saat menempelkan kode CSS atau HTML tanpa kode khusus dan menempelkan kode di salah satu dari dua mode pembuatan. Menurut pengembangan
, versi html terbaru adalah html5, tetapi sekali lagi kami telah membuat daftar periksa untuk versi html5 terbaru. Di bawah ini adalah kode warna HTML lengkap berdasarkan kode heksadesimal dan RGB. Oleh karena itu, harus ditempatkan setelah kode HTML. Tempel kode HTML ke halaman. Selain itu, ada fitur penyorotan sintaks yang menunjukkan arti dari kode saat ini. dabblet menyediakan lembar kerja terpisah untuk bekerja dengan HTML, CSS, dan JS.
Kode warna html (hypertext markup language) ditandai dengan enam karakter setelah tagar (#), misalnya #000000. Html editor ini juga memiliki color picker yang berguna untuk mengatur style html dan mouse hover yang memberikan anda informasi ketika mengarahkan kursor ke kode tertentu. Pengertian html adalah bahasa markup web, kepanjangan html adalah hypertext markup language. Dalam kode javascript diatas, saya memakai 2 buah method addeventlistener, untuk setiap tombol. Jika semua fitur di atas masing kurang, anda masih bisa menambahkan fungsi lain dengan memasang extension yang bisa anda pilih di marketplace mereka.
Deskripsi singkat tentang HTML dan kode. HTML adalah bahasa markup Internet (Web) dalam bentuk kode dan simbol yang disisipkan ke dalam file yang ditampilkan. Tempel kode HTML ke halaman. Html adalah singkatan dari Hypertext Markup Language. HTML adalah bahasa markup web dan HTML adalah singkatan dari hypertext markup language. Jika Anda baru mengenal
HTML, Anda bisa mendapatkan beberapa wawasan di bagian ini. Misalnya, jika Anda ingin teks menjadi miring atau miring, tulis kode
- untuk miring,
- untuk tebal, dan
untuk teks yang digarisbawahi pada halaman HTML Anda. Untuk protokol, seluruh kode HTML harus ditulis dalam tag HTML. Oleh karena itu, harus ditempatkan setelah kode HTML. Bookmark HTML membutuhkan sampul seni agar triknya berfungsi. Kode atau konten HTML berikutnya tidak dianggap sebagai kelanjutan penanda.
Tetapi sampai beberapa tahun yang lalu, tidak ada prosedur standar. Html adalah singkatan dari Hypertext Markup Language. Selain itu, ada fitur penyorotan sintaks yang menunjukkan arti dari kode saat ini. dabblet menyediakan lembar kerja terpisah untuk bekerja dengan HTML, CSS, dan JS. Pemrosesan dan Kode HTML: HTML adalah singkatan dari hypertext markup. Bahasa adalah bahasa web atau markup internet yang merupakan kombinasi teks dan informasi dalam bentuk simbol atau kode yang dimasukkan ke dalam file untuk mengidentifikasi web yang Anda buat. .. halaman. Tempelkan kode HTML pada halaman
. Berikut adalah beberapa tag HTML dasar yang biasa digunakan dalam desain situs web dan contoh fitur dan penggunaannya, tanpa usaha ekstra. Editor HTML juga memiliki pemilih warna yang membantu Anda mengatur gaya HTML dan penunjuk mouse yang memberikan informasi saat Anda mengarahkan kursor ke kode tertentu. Artikel ini menjelaskan beberapa tag HTML dasar. Banyak fitur html5 tidak memerlukan Adobe Flash untuk memutar video.
Langkah ada di langkah 2. Anda juga dapat menggunakan Html5 untuk membuat aplikasi lintas platform seperti Android, iOS dan Windows Phone. Pengertian HTML Apa itu HTML? Bagian ini tidak menjelaskan cara mengedit kode HTML. Setelah mengetahui pengolahan dan kode HTML/arti HTML dan penggunaan HTML.
Dan semua halaman kode besar dimasukkan ke dalam struktur ini setelah dipangkas. Baris kode di atas menerapkan latar belakang biru, paragraf 20 piksel, dan font “biru sedang” ke satu halaman HTML. Bagian ini tidak menjelaskan cara mengedit kode HTML. Anda dapat membebaskan Javascript dari kode HTML Anda dengan menggunakan addeventlistener. Pengerjaan dan kode html
Pertambahan panjang pegas tersebut adalah. Javascript melakukan interaksi dengan pengguna langsung disisi klien. Oleh sebab itu, kita perlu menempatkannya sesudah kode html. Html sampai saat ini merupakan standar di internet yang didefinisikan dan. Untuk menerapkan kode google survei di laman web, anda harus mengedit kode html laman anda.
Editor HTML ini juga memiliki pemilih warna untuk membantu Anda mengatur gaya HTML dan gerakan mouse yang memberikan informasi saat Anda mengarahkan kursor ke kode tertentu.
Hypertext Markup Language (html) digunakan untuk membuat halaman web, menampilkan berbagai informasi di browser web Internet, dan menulis format hypertext sederhana dalam file ASCII untuk menghasilkan tampilan formulir bawaan Bahasa markup yang digunakan.
HTML, singkatan dari hypertext markup language, adalah bahasa web, atau Internet markup, kombinasi teks dan informasi dalam bentuk simbol atau kode yang ditempatkan dalam file untuk membuat halaman web. Template blog Blogger
terdiri dari tiga bagian utama kode: CSS, HTML, dan Javascript, yang dikompilasi ke dalam file XML.
![]()
![]()
![]()
![]()
![]()
Penerapan Memoisasi Pada Prosesor Aquery Streaming
zorba-xquery – Dalam makalah ini, kami menjelaskan pendekatan untuk meningkatkan kinerja mesin XQuery dengan mengidentifikasi dan memanfaatkan peluang untuk berbagi pemrosesan baik di dalam maupun di seluruh kueri XML. Kami pertama-tama menjelaskan di mana peluang berbagi muncul di dunia pemrosesan kueri XML.
Penerapan Memoisasi Pada Prosesor Aquery Streaming – Kami kemudian menjelaskan pendekatan untuk pemrosesan XQuery bersama berdasarkan memoisasi, memberikan detail implementasi yang kami bangun dengan memperluas prosesor streaming XQuery yang digabungkan dengan BEA Systems sebagai bagian dari produk BEA WebLogic Integration 8.1 mereka. Untuk mengeksplorasi potensi keuntungan kinerja yang ditawarkan oleh pendekatan kami, kami menyajikan hasil dari studi eksperimental kinerjanya melalui kumpulan beban kerja kueri sintetis yang terinspirasi kasus penggunaan. Hasil kinerja menunjukkan bahwa keuntungan keseluruhan yang signifikan memang tersedia.
Penerapan Memoisasi Pada Prosesor Aquery Streaming

XQuery , meskipun belum menjadi standar, sudah digunakan untuk produk infrastruktur perangkat lunak komersial saya untuk sejumlah tujuan TI yang berbeda. Misalnya, bahasa XQuery (dan sub-bahasa XPath) telah dimasukkan ke dalam beberapa produk untuk manajemen proses bisnis dan integrasi aplikasi. XQuery digunakan dalam beberapa cara di sana – sebagai bahasa transformasi untuk mendefinisikan transformasi data XML, sebagai bahasa ekspresi untuk membuat keputusan percabangan dan perulangan berdasarkan variabel alur kerja XML, dan sebagai bahasa pemfilteran dan perutean untuk menangani peristiwa perantara pesan. XQuery juga digunakan dalam produk integrasi informasi perusahaan yang menyediakan tampilan XML virtual dari sumber data perusahaan yang berbeda yang merupakan bahasa untuk mendefinisikan tampilan terintegrasi dan menulis kueri.
Saat adopsi XQuery mendapatkan momentum, kinerja pemrosesan XQuery menjadi semakin penting. Seperti halnya bahasa kueri apa pun, XQuery dapat menerima sejumlah besar pengoptimalan, baik pada waktu kompilasi maupun saat runtime. Dalam banyak penggunaan XQuery, peluang pengoptimalan yang signifikan dapat diperoleh melalui penemuan dan eksploitasi pemrosesan bersama, di dalam atau di seluruh kueri. Misalnya, dalam publikasi/langganan, pekerjaan evaluasi kueri dapat dibagikan saat mencocokkan pesan dengan sejumlah besar langganan.
Dalam makalah ini, kami menyelidiki eksploitasi peluang berbagi tersebut untuk meningkatkan kinerja pemrosesan XQuery. Secara khusus, kami mengembangkan teknik memoisasi untuk XQuery dan menerapkannya dalam konteks prosesor XQuery streaming komersial. Berbagi dalam pemrosesan XQuery. Secara intuitif, hasil antara pemrosesan XQuery dapat dibagikan kapan pun ekspresi XQuery “sama” akan dievaluasi lebih dari sekali dengan binding variabel XQuery “sama”. (Kami akan mengatakan lebih banyak tentang apa arti “sama” dalam konteks ini di Bagian 2.) Hal ini dapat terjadi dalam beberapa cara:
1. Ekspresi yang sama dapat muncul beberapa kali di lokasi berbeda dalam kueri.
2. Ekspresi yang sama dapat muncul dalam kueri berbeda yang dievaluasi bersama.
3. Ekspresi dapat terjadi dalam kueri yang dievaluasi beberapa kali (kemungkinan besar dengan ikatan variabel yang berbeda).
4. Ekspresi dapat muncul dalam kueri berbeda yang dijalankan pada waktu berbeda (dengan konteks kueri yang sama di seluruh eksekusi).
Kasus pertama cukup jelas. Kasus kedua muncul dalam konteks seperti terbitkan/berlangganan, di mana pesan XML yang masuk perlu diperiksa terhadap banyak kueri berlangganan. Contoh kasus ketiga dan keempat adalah panggilan layanan web atau pencarian basis data jarak jauh yang dimodelkan sebagai panggilan fungsi XQuery, di mana hasil panggilan diketahui stabil dari waktu ke waktu (setidaknya untuk jangka waktu tertentu). Dalam karya ini, kami mengusulkan pendekatan berbasis memoisasi untuk menghindari pekerjaan yang berlebihan. Memoisasi menyimpan hasil untuk ekspresi berdasarkan pengikatan variabelnya, dan dengan demikian dapat mendukung penggunaan kembali evaluasi dalam semua kasus di atas.
Baca Juga : Mengapa menyimpan data XML dalam database SQL Server?
Streaming pemrosesan XQuery. Pendekatan kami dirancang untuk bekerja dengan baik dalam konteks prosesor kueri XML yang menggunakan pemrosesan berbasis aliran. Dalam konteks pemrosesan kueri XML, streaming penting untuk kinerja, dan itu dapat terjadi pada tingkat perincian yang bagus. Pendekatan berbutir halus sangat penting mengingat bahwa satu item XML dapat berukuran besar secara sewenang-wenang, berisi konten data yang setara dengan seluruh tabel atau bahkan database. Untuk mengaktifkan streaming berbutir halus, mesin BEA XQuery , mesin yang menjadi dasar pekerjaan ini, mewakili operan XML-nya sebagai urutan token (yang berpotensi bersarang) yang mewakili potongan data konstituen yang lebih kecil.
Penggunaan representasi aliran token XML menyediakan prosesor XQuery dengan beberapa cara untuk mencapai evaluasi kueri tambahan sambil menghindari materialisasi inputnya. Cara pertama adalah pipelining. Ekspresi XQuery yang diberikan dapat menggunakan dan menghasilkan aliran token secara bertahap, hanya mewujudkan satu atau beberapa token pada satu waktu untuk menghitung dan memancarkan outputnya. Tentu saja, ini membutuhkan penggunaan API berbasis tarikan agar benar-benar efektif. Cara kedua adalah lazy evaluation, teknik yang biasa digunakan dalam implementasi bahasa pemrograman fungsional. Dengan teknik ini, hasil tidak benar-benar dihasilkan sampai diminta oleh ekspresi konsumsi. Selain itu, di XQuery, beberapa ekspresi dapat dievaluasi hanya berdasarkan beberapa token pertama dari input yang diberikan – misalnya, nth(), empty(), existing(), komparator eksistensial, dan predikat posisional. Ekspresi ini memungkinkan mode yang lebih malas untuk pemrosesan XQuery, di mana hanya token yang (mungkin sedikit) yang diperlukan untuk ekspresi konsumsi yang dihasilkan.
Kontribusi. Dalam makalah ini, kami menyajikan pendekatan berbasis memoisasi untuk berbagi dalam pemrosesan XQuery. Sementara masalah pemrosesan kueri ganda (MQP) dan penggunaan memoisasi untuk pemrosesan kueri telah dieksplorasi dalam konteks lain, kontribusi kami terletak pada kenyataan bahwa pemrosesan kueri XQuery bersama dalam lingkungan streaming menambahkan kerutan baru yang signifikan pada masalah. Secara khusus, MQP dalam pengaturan relasional telah berfokus pada konstruksi gaya SELECT FROM-WHERE, sedangkan pekerjaan kami ditujukan untuk mendukung berbagi untuk bahasa XQuery yang jauh lebih kaya. Memoisasi telah dieksploitasi untuk fungsi yang mahal (seperti dalam pemrosesan kueri) atau fungsi yang dihitung berulang kali (seperti dalam pemrograman dinamis), tetapi belum dipelajari untuk berbagai macam ekspresi XQuery dan dalam lingkungan pemrosesan berbasis aliran. Kontribusi utama dari karya ini dapat diringkas sebagai berikut:
1. Kami menetapkan cakupan untuk memoisasi XQuery, pertama dengan cara yang sederhana namun terbatas, dan kemudian dalam rentang yang diperluas dengan memanfaatkan data semantik dan kesetaraan ekspresi.
2. Kami mengembangkan sejumlah teknik kompilasi kueri untuk mengidentifikasi ekspresi XQuery yang dapat dibagikan dan untuk menentukan rincian memoisasi.
3. Kami juga memperluas sistem runtime, menyelesaikan ketegangan yang melekat antara pemrosesan berbasis aliran dan memoisasi. Solusi kami memungkinkan penggunaan kembali komputasi sambil mendukung pipelining dan menghindari evaluasi yang bersemangat.
4. Kami merangkum hasil dari studi kinerja teknik kami dalam konteks mesin BEA XQuery. Hasilnya menunjukkan peningkatan kinerja yang signifikan untuk kasus penggunaan khas XQuery.
5. Karena makalah ini mewakili pendekatan awal kami untuk menambahkan memoisasi ke pemrosesan XQuery, kami mengidentifikasi beberapa masalah terbuka yang penting untuk ditangani.
![]()
![]()
![]()
![]()
![]()
Mengapa menyimpan data XML dalam database SQL Server?
Mengapa menyimpan data XML dalam database SQL Server? – Terkadang, XML tampak seperti konvensi membingungkan yang menawarkan solusi untuk masalah yang tidak dimiliki oleh pengguna database rata-rata. Untuk memperburuk keadaan, para ahli XML umumnya tidak memiliki sarana untuk memberikan jawaban sederhana bahkan untuk pertanyaan yang paling sederhana sekalipun. Rob Sheldon, sebaliknya, dapat menjawab bahkan pertanyaan-pertanyaan yang entah bagaimana kita merasa konyol bertanya di depan umum, dan berpikir dua kali untuk melakukannya.
Mengapa menyimpan data XML dalam database SQL Server?
zorba-xquery – Mengapa menyimpan data XML dalam database SQL Server? Mengapa tidak menyimpan XML sebagai dokumen dalam sistem file saja?
Dalam beberapa kasus, sistem file mungkin baik-baik saja, jika Anda tidak berencana untuk mengaitkan file dengan data apa pun di database SQL Server Anda dan Anda tidak ingin memanfaatkan fitur khusus XML apa pun yang disediakan SQL Server , seperti dapat mengaitkan data relasional dengan data dalam instance XML. Misalnya, Anda memiliki database yang menyimpan informasi produk. Untuk setiap produk, Anda memelihara dokumen XML yang menyediakan detail tentang produk tersebut. Dengan menyimpan dokumen di dalam database, Anda bisa membuat kueri yang mengambil data relasional dan informasi spesifik dalam instance XML yang terkait dengan data tersebut.
Di SQL Server, Anda biasanya menyimpan data XML dalam kolom yang dikonfigurasi dengan tipe data xml. Tipe data mendukung beberapa metode yang memungkinkan Anda membuat kueri dan memodifikasi elemen individual, atribut, dan nilainya secara langsung dalam instance XML, daripada harus bekerja dengan instance itu secara keseluruhan. Selain itu, tipe data xml memastikan bahwa setiap instance XML, setidaknya, dibentuk dengan baik menurut standar ISO. Dan jika Anda mengaitkan kumpulan skema dengan kolom xml Anda, Anda dapat memvalidasi lebih lanjut struktur dan datanya.
Baca Juga : Prosesor XQuery Paralel yang Dapat Diskalakan
SQL Server juga menyediakan beberapa opsi untuk mengindeks kolom xml Anda, dengan fitur yang diperluas mulai dari SQL Server 2012. Selain itu, menyimpan XML Anda dalam database SQL Server memungkinkan Anda memanfaatkan kemampuan administratif dan mekanisme akses data SQL Server, seperti OLE DB dan ADO.NET. Bahkan jika Anda tidak menyimpan data dalam kolom xml, Anda masih dapat memanfaatkan penyimpanan dan kemampuan akses SQL Server lainnya. Yang mengatakan, jika Anda tidak memerlukan salah satu fitur ini, Anda mungkin tidak memerlukan SQL Server. Lihatlah bagaimana Anda berencana untuk mengakses dan memodifikasi file XML Anda, lalu putuskan.
Apa yang membuat dokumen XML berbeda dari file teks biasa?
Dokumen XML adalah dokumen yang sesuai dengan aturan pemformatan ISO yang mengatur eXtensible Markup Language (XML). Seperti namanya, XML adalah bahasa berbasis teks yang mirip dengan HTML. Ini menggunakan tag untuk menggambarkan sifat data dan bagaimana data harus diformat. Tidak seperti HTML, bagaimanapun, XML memungkinkan Anda menentukan tag Anda sendiri, dengan demikian sifatnya yang dapat diperluas, itulah sebabnya XML sering disebut sebagai bahasa yang menggambarkan diri sendiri. Karena telah diadopsi secara universal, Anda dapat menggunakannya untuk berbagi berbagai data di seluruh sistem yang heterogen, selama XML sesuai dengan standar ISO.
Dokumen XML mencakup dua tipe dasar informasi: data itu sendiri dan tag yang mengatur dan mendeskripsikan data. XML berikut menunjukkan komponen dasar dokumen XML:
Elemen mewakili blok bangunan dalam instance XML. Mereka menyertakan tag yang diapit tanda kurung sudut dan data di antara tag tersebut. Semua elemen berisi tag pembuka dan tag akhir, seperti <Mobil> dan </Mobil>, masing-masing. Di antara tag pembuka dan akhir, Anda akan menemukan elemen turunan, data, atau keduanya. Misalnya, elemen <Mobil> disematkan di elemen <Mobil>, dengan elemen turunan seperti <Buat> dan <Model> yang berisi data aktual.
Selain itu, tag pembuka elemen dapat menyertakan atribut, seperti id=”1234″, yang merupakan kombinasi dari nama atribut (id) dan nilainya (1234). Anda juga akan melihat bahwa XML dimulai dengan jenis tag khusus yang disebut deklarasi. Deklarasi menentukan versi XML mana yang digunakan dan secara opsional dapat menyertakan informasi pengkodean. Dalam hal ini, deklarasi menunjukkan bahwa data disimpan sebagai urutan karakter Unicode 8-bit.
Contoh dasar ini juga menunjukkan sifat hierarkis XML dan sifatnya yang menggambarkan dirinya sendiri. Kita bisa dengan mudah membuat struktur XML yang menggambarkan orang, tempat, atau hal lainnya. Meskipun XML tidak lain hanyalah teks sederhana, format yang menggambarkan dirinya sendiri memungkinkannya meneruskan data ke berbagai sistem. Selama aplikasi seperti SQL Server memiliki kapasitas untuk mengurai XML dan XML itu sesuai dengan standar ISO, tidak ada batasan untuk jenis data yang dapat Anda lewati di antara sistem yang heterogen. Penerimaan universal dan metodologi standarnya menjadikannya cara yang sederhana namun efektif untuk memindahkan data antar aplikasi yang melayani fungsi yang berbeda dan didasarkan pada teknologi yang berbeda.
Apa yang dimaksud dengan instance XML di SQL Server, sebagai lawan dari dokumen XML?
Anda akan sering menemukan bahwa dokumentasi SQL Server mengacu pada XML yang disimpan dalam objek xml (kolom, variabel, atau parameter) sebagai instance XML. Ini karena SQL Server mendukung dokumen XML dan fragmen XML, keduanya dianggap sebagai instance XML. Meskipun Anda akan sering melihat istilah instance XML dan dokumen XML yang digunakan dapat dipertukarkan, sebenarnya, keduanya berbeda, dengan dokumen menjadi jenis instance, seperti halnya fragmen. Anda dapat menyimpan dokumen XML atau fragmen dalam objek xml . Namun, jika Anda mengaitkan objek itu dengan kumpulan skema, Anda bisa menentukan bahwa hanya dokumen yang diizinkan. Untuk dianggap sebagai dokumen, instance XML harus memiliki hanya satu elemen root, tanpa teks yang ditentukan di tingkat atas.
Saat menyimpan dokumen XML dalam database SQL Server, haruskah Anda selalu menggunakan tipe data xml?
Tidak, Anda tidak harus. Dalam beberapa kasus, Anda harus menggunakan penyimpanan objek besar seperti varchar(max) atau nvarchar(max). Itu semua tergantung pada bagaimana Anda akan mengakses dan memperbarui instance XML dan apakah Anda ingin memvalidasi struktur XML.
Tipe data xml mengharuskan semua XML dibentuk dengan baik sesuai dengan standar ISO, yang menentukan bagaimana elemen XML harus diformat. Anda bahkan dapat mengambil langkah lebih jauh dengan mengaitkan kumpulan skema dengan kolom xml Anda. Kumpulan skema berisi satu atau beberapa skema XML yang menentukan tipe elemen dan atribut yang dapat dikandung oleh instance XML. Skema juga lebih ketat mendefinisikan jenis nilai yang dapat dikaitkan dengan elemen atau atribut.
Selain itu, tipe data xml mendukung sekumpulan metode yang memungkinkan Anda mengkueri elemen dan atribut tertentu dalam instance XML. Misalnya, misalkan kolom xml Anda menyimpan semua informasi kontak yang terkait dengan setiap pelanggan. Data mungkin termasuk alamat email, nomor telepon, pegangan jejaring sosial, dan alamat fisik. Dari kolom ini, Anda dapat mengambil alamat email atau menambahkan nomor ponsel atau mengubah alamat rumah. Plus, Anda dapat menentukan indeks XML pada kolom xml jika beban kerja kueri Anda biasanya menyertakan kolom tersebut.
Namun, dalam beberapa kasus, Anda tidak memerlukan fitur apa pun yang disediakan oleh tipe data xml. Misalnya, Anda mungkin menyimpan manual produk yang hanya diakses secara keseluruhan. Jika manual diubah, nilai xml itu sendiri diganti dengan dokumen baru. Anda tidak perlu menanyakan atau memodifikasi komponen individual, dan Anda tidak peduli dengan XML yang divalidasi. Dalam situasi seperti ini, Anda harus menggunakan tipe data objek besar untuk menghindari proses validasi tambahan yang dilakukan mesin database untuk kolom xml. Secara umum, setiap kali aplikasi Anda hanya menyimpan dan mengambil seluruh instance XML atau Anda ingin mempertahankan instance XML dalam bentuk aslinya, seperti halnya dengan dokumen legal, Anda harus tetap menggunakan penyimpanan objek besar.
Apa artinya kolom xml diketik?
Kolom xml yang diketik (atau variabel atau parameter) merujuk ke kolom yang terikat ke kumpulan skema XML dalam SQL Server. Kumpulan skema adalah kumpulan satu atau beberapa skema XML yang menentukan struktur yang diizinkan dari instance XML yang disimpan dalam kolom tersebut.
Skema menentukan jenis elemen dan atribut yang diizinkan dalam XML dan bagaimana komponen tersebut harus diurutkan dan dipertahankan secara hierarkis. Skema juga menentukan jenis nilai yang diizinkan dalam elemen atau atribut (seperti string atau bilangan bulat) dan berapa kali elemen dapat dimasukkan. Misalnya, skema mungkin menentukan bahwa harus ada tepat satu elemen anak <FirstName> dalam setiap elemen <Customer> dan nilai <FirstName> harus berupa string.
Saat Anda memasukkan contoh XML ke dalam kolom xml yang tidak diketik, mesin database memvalidasi XML untuk memastikan bahwa itu terbentuk dengan baik. Saat Anda memasukkan instance XML ke dalam kolom yang diketik, mesin memastikan bahwa XML terbentuk dengan baik dan mematuhi struktur yang lebih kaku yang ditentukan dalam skema terkait.
Anda harus menggunakan kolom xml yang diketik setiap kali Anda memiliki kumpulan skema yang diperlukan dan Anda ingin SQL Server memvalidasi XML terhadap skema tersebut. Jika Anda tidak memiliki koleksi skema atau tidak ingin mengaitkan kolom xml dengan koleksi yang Anda miliki, gunakan kolom yang tidak diketik.
![]()
![]()
![]()
![]()
![]()
Prosesor XQuery Paralel yang Dapat Diskalakan
zorba-xquery – Penggunaan XML yang luas untuk manajemen dokumen dan pertukaran data telah menciptakan kebutuhan untuk melakukan query terhadap repositori data XML yang besar. Untuk membuat kueri data sebesar itu secara efisien dan memanfaatkan paralelisme, kami telah menerapkan Apache VXQuery, prosesor XQuery sumber terbuka yang dapat diskalakan. Sistem ini dibangun di atas dua kerangka kerja sumber terbuka lainnya: Hyracks, mesin eksekusi paralel, dan Algebricks, kotak alat kompiler agnostik bahasa.
Prosesor XQuery Paralel yang Dapat Diskalakan – Apache VXQuery memperluas kerangka kerja ini dan menyediakan implementasi spesifik XQuery (model data, fungsi dan pengoptimalan yang bergantung pada model data, dan parser). Kami menjelaskan arsitektur Apache VXQuery, integrasinya dengan Hyracks dan Algebricks, dan aturan pengoptimalan XQuery yang diterapkan pada rencana kueri untuk meningkatkan efisiensi ekspresi jalur dan untuk mengaktifkan paralelisme kueri. Evaluasi eksperimental menggunakan set data 500GB nyata dengan berbagai pilihan, agregasi, dan bergabung dengan kueri XML menunjukkan bahwa Apache VXQuery berkinerja baik baik dalam hal peningkatan skala dan kecepatan. Eksperimen kami menunjukkan bahwa ini sekitar 3,5x lebih cepat daripada Saxon (prosesor XQuery open-source dan komersial) pada implementasi 4-core, node tunggal, dan sekitar 2,5x lebih cepat daripada Apache MRQL (prosesor kueri paralel berbasis MapReduce) pada delapan (4-core) node cluster.
Prosesor XQuery Paralel yang Dapat Diskalakan
Penerimaan luas XML sebagai standar untuk manajemen dokumen dan pertukaran data telah memungkinkan pembuatan repositori data XML yang besar. Untuk secara efisien meminta koleksi data besar seperti itu, diperlukan implementasi XQuery yang dapat diskalakan yang dapat memanfaatkan paralelisme. Meskipun ada berbagai prosesor XQuery open-source asli (Saxon , Galax , dll.) mereka telah dioptimalkan untuk pemrosesan node tunggal dan tidak mendukung penskalaan ke banyak node. Untuk membuat prosesor XQuery yang dapat diskalakan, seseorang dapat: 1) menambahkan skalabilitas ke prosesor XQuery yang ada, 2) memulai dari awal, atau 3) memperluas kerangka kerja kueri skalabel yang ada untuk mendukung XQuery. Sayangnya, prosesor XQuery yang ada akan membutuhkan penulisan ulang yang ekstensif dari fitur arsitektur inti mereka untuk menambahkan paralelisme. Demikian pula, membangun prosesor XQuery dari awal akan melibatkan pemrograman skalabel kompleks yang sama (beberapa tidak terkait dengan model data XML). Opsi terakhir, memperluas kerangka kerja terukur yang ada untuk mendukung XQuery, tampaknya menguntungkan karena menggabungkan manfaat teknologi paralel yang telah terbukti dengan waktu implementasi yang lebih singkat.
Di antara beberapa kerangka kerja terukur yang tersedia, seseorang dapat menggunakan mesin basis data paralel relasional dan memanfaatkan teknik pengoptimalannya yang matang. Namun, ini memerlukan biaya tambahan untuk menerjemahkan data/kueri ke model relasional dan kembali ke XML; selain itu, kueri jalur XML yang panjang dapat menghasilkan banyak gabungan. Pendekatan lain adalah membangun prosesor XQuery di atas kerangka MapReduce. Contohnya termasuk ChuQL , yang merupakan ekstensi MapReduce ke XQuery yang dibangun di atas Hadoop, dan HadoopXML , yang menggabungkan banyak kueri XPath menjadi beberapa pekerjaan Hadoop MapReduce. Demikian pula, Apache MRQL menerjemahkan kueri XPath ke dalam bahasa seperti SQL yang diimplementasikan melalui operator MapReduce. Namun, pendekatan berbasis Hadoop ini terbatas karena hanya dapat menggunakan beberapa operator MapReduce yang tersedia (yaitu memetakan, mengurangi, dan menggabungkan).
Baca Juga : Mengulas Tentang XQuery Design Patterns
Baru-baru ini, kerangka kerja telah diusulkan yang menggeneralisasi
model eksekusi MapReduce dengan mendukung sekumpulan operator yang lebih besar untuk membuat pekerjaan paralel (termasuk Hyracks , Spark , dan Stratosphere ). Sistem ‘aliran data’ seperti itu biasanya mencakup model data fleksibel yang mendukung berbagai format data (relasional, semi terstruktur, teks, JSON, XML, dll.) yang membuatnya mudah diperluas. Dalam makalah ini, kami menggunakan Hyracks sebagai kerangka kerja paralel kami dan menggunakan Algebricks , kotak alat kompiler agnostik bahasa, untuk mengimplementasikan XQuery. Implementasi kami tersedia sebagai open source di ASF. Kami telah melakukan evaluasi eksperimental menggunakan kumpulan data nyata yang besar (500GB) (dataset cuaca NOAA dari ) dan berbagai pilihan, agregasi, dan kueri gabungan XML yang menunjukkan efisiensi prosesor XQuery kami, baik dalam hal kecepatan dan peningkatan.
Sisa makalah ini disusun sebagai berikut: Bagian II meninjau pendekatan saat ini untuk menanyakan repositori data XML besar sementara Bagian III mencakup tumpukan perangkat lunak Apache VXQuery dengan detail tentang kerangka kerja yang mendasarinya (Hyracks dan Algebricks) dan bagaimana model data, parser, dan runtime diperpanjang untuk dukungan XQuery. Mengingat spesifikasi XQuery, kami harus memperluas aturan penulisan ulang Aljabar yang ada dan memperkenalkan yang baru; diskusi ini muncul di Bagian IV. Terakhir, Bagian V menyajikan hasil eksperimen kami tentang kinerja Apache VXQuery serta perbandingan dengan dua prosesor XML open-source – SaxonHE single-threaded dan Apache MRQL paralel.
Hadoop menyediakan kerangka kerja untuk pemrosesan terdistribusi berdasarkan model MapReduce. Itu meninggalkan beban implementasi yang signifikan pada programmer aplikasi. Akibatnya, sejumlah bahasa telah diusulkan di atas Hadoop (misalnya Hive , PigLatin , dan Jaql ); namun, bahasa MapReduce tingkat tinggi yang populer tidak mendukung model data XML. Pendekatan terbaru untuk menutup kesenjangan ini meliputi: ChuQL, Apache MRQL, HadoopXML, dan Oracle XQuery untuk Hadoop. ChuQL memperluas XQuery untuk menyertakan dukungan MapReduce untuk memproses XML asli di Hadoop. Di ChuQL, ekspresi MapReduce disertakan sebagai fungsi XQuery, memungkinkan penulis kueri untuk menentukan definisi pekerjaan MapReduce di XQuery. Sebaliknya, VXQuery menyembunyikan semua detail pemrosesan paralel dari penulis kueri saat masih menggunakan konstruksi XQuery standar. Apache MRQL (MapReduce Query Language), adalah bahasa seperti SQL yang dirancang untuk menjalankan tugas analisis data besar. Bahasa ini mendukung penguraian data XML dari Hadoop melalui ekspresi sumber yang mendefinisikan parser XML, file XML, dan tag XML. Pengurai XML memproses file XML dan mengembalikan semua elemen yang cocok dengan tag ini; Apache MRQL kemudian menerjemahkan elemen-elemen ini ke dalam model data Apache MRQL. Setiap kueri diterjemahkan ke ekspresi aljabar untuk pengoptimal berbasis biaya Apache MRQL, yang dibangun berdasarkan kueri relasional yang diketahui dan teknik pengoptimalan MapReduce. Aljabar menggunakan sejumlah kecil operator fisik untuk membuat pekerjaan MapReduce yang lebih efisien daripada langsung menulisnya menggunakan operator MapReduce. HadoopXML memproses satu file XML besar dengan serangkaian kueri yang telah ditentukan (masing-masing saat ini dalam subset XPath). Mesin mengidentifikasi kesamaan kueri (jalur yang umum) dan mengeksekusinya sekali; itu kemudian membagikan hasil umum dan menambahkannya dengan bagian yang tidak umum per kueri. Pemrosesan ini dilakukan menggunakan pekerjaan MapReduce. Saat kueri dijalankan, pengoptimal kueri menentukan jumlah pekerjaan yang optimal untuk mengeksekusi kueri yang diminta.
![]()
![]()
![]()
![]()
![]()

Mengulas Tentang XQuery Design Patterns
zorba-xquery – Pola desain banyak digunakan di dalam komunitas berorientasi objek. Mereka terbukti matang dan solusi yang dapat digunakan kembali yang memfasilitasi pengembangan modul dengan kopling minimal. Selain itu, pola desain juga merupakan konstruksi tingkat tinggi yang berkontribusi untuk meningkatkan komunikasi antar pengembang.Saat ini, XQuery dan keluarga spesifikasinya digunakan lebih dari sekadar menanyakan koleksi dan dokumen XML. XQuery semakin banyak digunakan sebagai bahasa pemrograman multi-paradigma yang lengkap. Tujuan dari makalah ini adalah (1) untuk memotivasi kebutuhan pola desain XQuery menggunakan contoh aplikasi dunia nyata dan (2) untuk mengeksplorasi keberadaan solusi desain umum untuk memecahkan masalah berulang dalam aplikasi XQuery skala besar.
Mengulas Tentang XQuery Design Patterns – Seperti yang dijelaskan di awal bagian ini, masalah seperti itu telah dipecahkan dalam komunitas berorientasi objek dengan mengembangkan dan menerapkan pola desain. Didorong oleh pengamatan ini, kami memutuskan untuk mulai menggunakan pola desain untuk mengatasi ketidaksesuaian yang dijelaskan di atas. Selain memotivasi penggunaan pola desain untuk XQuery, kontribusi makalah ini adalah (1) untuk mengidentifikasi ketidaksesuaian dalam aplikasi dunia nyata dan (2) untuk menunjukkan bagaimana ketidaksesuaian ini dapat diperbaiki dengan menggunakan pola desain. Secara khusus, kami menyajikan empat pola desain dan menjelaskan bagaimana masing-masing pola tersebut memecahkan satu masalah desain tertentu dalam aplikasi contoh (yang sedang berjalan) kami.
Mengulas Tentang XQuery Design Patterns
Sisa dari makalah ini disusun sebagai berikut. Di Bagian 2, kami menjelaskan kasus penggunaan untuk contoh kami yang sedang berjalan. Contoh ini akan digunakan untuk menunjukkan masalah desain yang ada dalam aplikasi dunia nyata. Di masing-masing dari empat bagian berikut (yaitu Bagian 3, 4, 5, dan 6), kami menyajikan satu pola desain untuk memecahkan salah satu masalah desain yang diidentifikasi. Bagian 7 menyimpulkan makalah dan memberikan pandangan tentang pekerjaan di masa depan
Menjalankan Contoh: Aplikasi AtomPub
Protokol Penerbitan Atom (AtomPub; lihat RFC5023) adalah protokol berbasis HTTP untuk membuat dan memperbarui sumber daya di web. Akhir-akhir ini, menjadi banyak digunakan untuk mengimplementasikan API untuk layanan cloud. Contoh yang paling menonjol mungkin adalah Protokol Data Google[1]. AtomPub dibangun di atas Format Sindikasi Atom yang merupakan representasi XML dari kumpulan sumber daya yang berubah-ubah (mis. umpan web). Oleh karena itu, XQuery sangat cocok untuk mengimplementasikan layanan (cloud) berbasis AtomPub.
Kami menggunakan aplikasi AtomPub untuk menyajikan pola desain untuk XQuery. Aplikasi ini sangat cocok untuk banyak pola (umum) karena sebagian besar komponennya harus dapat digunakan kembali oleh komponen aplikasi lainnya. Selain itu, memanfaatkan perpustakaan yang ada (misalnya untuk komunikasi dan otentikasi HTTP) memerlukan beberapa keputusan desain yang cermat untuk dibuat. Pada dasarnya, aplikasi AtomPub terdiri dari dua komponen utama: klien dan server. Klien adalah aplikasi XQuery yang harus mengimplementasikan dua kasus penggunaan dasar berikut:
Kasus Penggunaan 1: Kirim permintaan HTTP untuk membuat entri Atom.
Kasus Penggunaan 2: Kirim permintaan HTTP untuk mengambil entri Atom tertentu. Entri yang dihasilkan harus diubah menjadi HTML.
Server adalah aplikasi yang berjalan di dalam server aplikasi berkemampuan XQuery. Artinya, fungsinya dipicu oleh permintaan HTTP. Fungsi-fungsi tersebut memiliki akses ke konten permintaan HTTP menggunakan modul (HTTP) yang disediakan oleh server aplikasi. Server bertindak sebagai mitra untuk permintaan klien. Secara khusus, itu harus dapat menyelesaikan dua kasus penggunaan berikut:
Kasus Penggunaan 3: Menerima entri AtomPub dan menyimpannya. Seharusnya dimungkinkan untuk menyimpan entri di lokasi arbitrer seperti sistem file atau koleksi XQuery. Kasus Penggunaan 4: Posting pesan di Twitter untuk setiap entri yang dibuat dalam Kasus Penggunaan 3.
Di bagian selanjutnya dari makalah ini, kami menunjukkan bagaimana tantangan desain dalam mengimplementasikan use case yang dijelaskan dapat diselesaikan dengan memanfaatkan pola desain. Kita mulai dengan Kasus Penggunaan 1 dan 2 dari klien di Bagian 3 dan 4, masing-masing. Setelah itu, Bagian 5 dan 6 menjelaskan desain dan implementasi Use Cases 3 dan 4. Tabel berikut menggambarkan pemetaan kasus penggunaan, bagian, fitur XQuery yang diperlukan, dan nama pola yang digunakan untuk mengimplementasikan fitur yang dimaksud .
Baca Juga : Mari Kita Mempelajari XQuery Lebih Dalam Lagi
Pertimbangan Implementasi
Dalam implementasi yang disajikan di bagian terakhir, kami membuat beberapa keputusan untuk membuat esensi makalah lebih mudah dipahami dan meningkatkan keterbacaan kode. Keputusan ini juga tidak wajib untuk menerapkan Rantai Tanggung Jawab dan mungkin juga tidak optimal. Oleh karena itu pola ini dapat diimplementasikan di XQuery 1.0. Pada bagian ini, kami membahas beberapa aspek implementasi alternatif.
Pertimbangan 1: Implementasi klien, rantai fungsi yang berpartisipasi menggunakan XQuery Scripting. Namun, ada banyak cara untuk menerapkan chaining. Misalnya, rantai dapat diimplementasikan menggunakan Continuation Passing Style atau dengan menggunakan urutan item fungsi yang dieksekusi secara berurutan.
Pertimbangan 2: Keputusan lain yang kami ambil untuk membuat kode lebih tajam adalah dengan mengimplementasikan fungsi yang berpartisipasi menggunakan Fasilitas Pembaruan XQuery. Implementasi alternatif dapat menyalin dan mengubah elemen permintaan dan mengembalikannya sebagai hasil dari fungsi. Dalam hal ini, klien perlu memastikan bahwa elemen yang dikembalikan diteruskan sebagai argumen ke fungsi berikutnya.
Kesimpulan
Chain of Responsibility membantu kami meningkatkan fleksibilitas dan penggunaan kembali modul yang terlibat untuk mengimplementasikan Use Case 1. Hasilnya, kami memperoleh yang berikut:
Pengurangan kopling: Klien AtomPub telah dipisahkan dari Klien HTTP dan modul opsional lainnya seperti autentikasi HTTP, Klien OAuth, atau OpenID.
Fleksibilitas tambahan: Setiap fungsi dalam rantai dapat mengonfigurasi permintaan atau bahkan mengambil alih tanggung jawab untuk memproses permintaan. Lebih dari itu, kode dapat dengan mudah digunakan kembali dalam pengaturan yang berbeda. Misalnya, metode autentikasi yang berbeda dapat digunakan dengan mengganti fungsi http-auth:basic() dengan fungsi yang sesuai dari modul autentikasi yang berbeda.
Kesimpulan & Pandangan
Dalam makalah ini, kami memotivasi perlunya pola desain XQuery. Alasannya adalah karena semakin banyak aplikasi XQuery besar yang sebagian besar menunjukkan gejala yang terkenal di dunia berorientasi objek dan telah diselesaikan dengan menggunakan pola desain. Secara lebih rinci, kami telah menyajikan empat masalah desain di sepanjang contoh yang sedang berjalan. Selain itu, kami telah menunjukkan bagaimana masing-masing masalah ini dapat diselesaikan dengan menerapkan pola desain tertentu.
Kami telah memilih untuk menggunakan implementasi klien dan server AtomPub sebagai contoh yang berjalan. Untuk klien AtomPub, kami menggunakan Chain of Responsibility (lihat Bagian 3) yang menggunakan beberapa modul yang digabungkan secara longgar untuk membuat dan mengirim permintaan HTTP. Penerjemah (lihat Bagian 4) membantu kami menyediakan mesin rendering HTML yang fleksibel dan dapat diperluas untuk entri Atom. Untuk server AtomPub, Pola Strategi (Bag. 5) memungkinkan algoritme penyimpanan yang dapat dikonfigurasi dengan menampilkan fungsi tingkat tinggi. Terakhir, Pola Pengamat (Bag. 6) menyediakan cara untuk mendaftarkan layanan (misalnya pemberitahuan Twitter) yang secara otomatis diberi tahu jika keadaan objek yang diamati berubah.
Secara umum, aspek terpenting dari setiap pola yang disajikan dalam makalah ini adalah memisahkan fungsi dan modul XQuery. Misalnya, dalam Rantai Tanggung Jawab, kami mencapai ini dengan menghapus dependensi antar fungsi dengan menyetujui elemen Skema XML yang umum (yaitu item permintaan). Pola Strategi dan Pengamat sama-sama memanfaatkan fungsi tingkat tinggi sebagai mekanisme pemisahan.
Namun, empat pola yang disajikan dalam makalah ini hanyalah titik awal. Di masa mendatang, kami ingin mengembangkan katalog lengkap solusi desain yang dapat digunakan kembali untuk masalah desain XQuery yang paling sering terjadi. Selain itu, kami ingin mengklasifikasikan pola desain ini menurut (1) fitur bahasa (yaitu XQuery fungsional murni, Pembaruan XQuery, dan XQuery Scripting) dan (2) kategori (yaitu kreasi, struktural, dan perilaku).
![]()
![]()
![]()
![]()
![]()

Mari Kita Mempelajari XQuery Lebih Dalam Lagi
Pengantar
zorba-xquery – Tutorial XQuery ini untuk semua orang yang benar-benar ingin tahu apa itu XQuery, tetapi tidak punya waktu untuk mencari tahu. Kita semua tahu masalahnya: begitu banyak teknologi baru yang menarik, begitu sedikit waktu untuk menelitinya. Sejujurnya, saya harap Anda akan menghabiskan lebih dari sepuluh menit untuk tutorial XQuery ini — tetapi jika Anda benar-benar harus segera meninggalkannya, saya harap Anda tetap mempelajari sesuatu yang bermanfaat.
Mari Kita Mempelajari XQuery Lebih Dalam Lagi
– Untuk Apa XQuery?
Mari Kita Mempelajari XQuery Lebih Dalam Lagi – XQuery dirancang terutama sebagai bahasa kueri untuk data yang disimpan dalam bentuk XML. Jadi peran utamanya adalah untuk mendapatkan informasi dari database XML — ini termasuk database relasional yang menyimpan data XML, atau yang menyajikan tampilan XML dari data yang mereka pegang. Beberapa orang juga menggunakan XQuery untuk memanipulasi dokumen XML yang berdiri sendiri, misalnya, untuk mengubah pesan yang lewat di antara aplikasi. Dalam peran itu XQuery bersaing langsung dengan XSLT, dan bahasa mana yang Anda pilih sebagian besar merupakan masalah preferensi pribadi. Faktanya, beberapa orang sangat menyukai XQuery sehingga mereka bahkan menggunakannya untuk merender XML menjadi HTML untuk presentasi. Itu bukan benar-benar pekerjaan yang dirancang untuk XQuery, dan saya tidak akan merekomendasikan orang untuk melakukan itu, tetapi begitu Anda mengenal alat, Anda cenderung menemukan cara baru untuk menggunakannya.
– Bermain dengan XQuery
Cara terbaik untuk belajar tentang apa pun adalah dengan mencobanya sendiri. Dua cara Anda dapat mencoba contoh XQuery dalam artikel ini adalah:
Instal Stylus Studio – Lalu buka File > New > XQuery File… dan Anda dapat mulai membuat kueri di panel editor. (Di Stylus Studio, Anda juga dapat menggunakan XQuery mapper visual untuk membuat kueri Anda secara grafis. Jika Anda menyukai pendekatan itu, silakan. Tapi saya akan berkonsentrasi di sini pada sintaks bahasa yang sebenarnya.)
Unduh DataDirect XQuery – komponen pemrosesan XQuery berbasis Java untuk kueri data relasional, file XML, dan data non-XML menggunakan XQuery.
Baca Juga : Oracle Exec Lobi Untuk ‘Zorba’ Open-Source XQuery Engine
– XQuery Pertama Anda
Untuk yang satu itu, tentunya jarak tempuh bisa berbeda-beda. Ketepatan nilai waktu (fraksi detik) bergantung pada prosesor XQuery yang Anda gunakan, dan zona waktu (5 jam sebelum GMT dalam kasus ini) bergantung pada bagaimana sistem Anda dikonfigurasi. Tak satu pun dari ini adalah pertanyaan yang sangat berguna, tentu saja, dan apa yang mereka tunjukkan bukanlah ilmu roket. Tetapi dalam bahasa kueri, Anda harus dapat melakukan sedikit perhitungan, dan XQuery telah membahasnya. Lebih lanjut, XQuery dirancang sedemikian rupa sehingga ekspresi sepenuhnya dapat disarang — ekspresi apa pun dapat digunakan dalam ekspresi lain apa pun, asalkan memberikan nilai tipe yang tepat — dan ini berarti bahwa ekspresi yang terutama ditujukan untuk memilih data dalam klausa where juga dapat digunakan sebagai kueri yang berdiri sendiri dalam hak mereka sendiri.
– Mengakses Dokumen XML dengan XQuery
Meskipun mampu menangani tugas-tugas biasa seperti yang dijelaskan di bagian sebelumnya, XQuery dirancang untuk mengakses data XML. Jadi mari kita lihat beberapa kueri sederhana yang memerlukan dokumen XML sebagai inputnya. Dokumen sumber yang akan kita gunakan disebut videos.xml.
Ada juga salinan file contoh ini di Web. XQuery memungkinkan Anda untuk mengakses file secara langsung dari salah satu lokasi ini, menggunakan URL yang sesuai sebagai argumen untuk fungsi doc() nya. Inilah XQuery yang hanya mengambil dan menampilkan seluruh dokumen:
Fungsi yang sama dapat digunakan untuk mendapatkan salinan dari Web:
(Ini hanya akan berfungsi jika Anda online, tentu saja; dan jika Anda berada di belakang firewall perusahaan, Anda mungkin harus melakukan beberapa penyesuaian pada konfigurasi Java Anda untuk membuatnya berfungsi.)
URL tersebut agak berat, tetapi ada pintasan yang dapat Anda gunakan:
Jika Anda bekerja di Stylus Studio, klik XQuery / Scenario Properties, dan di bawah Main Input (opsional), telusuri file input dan pilih. Anda sekarang dapat merujuk ke dokumen ini dalam kueri Anda hanya sebagai “.” (dot). Jika Anda bekerja langsung dengan DataDirect XQuery, saya sarankan Anda menyalin file ke suatu tempat lokal, misalnya c:\query\videos.xml, dan bekerja dengannya dari lokasi itu. Gunakan opsi baris perintah -s c:\query\videos.xml dan Anda akan kembali dapat merujuk ke dokumen dalam kueri Anda sebagai “.
File berisi sejumlah bagian. Salah satunya adalah elemen <aktor>, yang bisa kita pilih seperti ini:
Itu adalah pertanyaan “nyata” pertama kami. Jika Anda terbiasa dengan XPath, Anda mungkin mengenali bahwa semua kueri sejauh ini adalah ekspresi XPath yang valid. Kami telah menggunakan beberapa fungsi — current-time() dan doc() — yang mungkin asing karena mereka baru di XPath 2.0, yang masih berupa draft; tetapi sintaks dari semua kueri sejauh ini adalah sintaks XPath biasa. Faktanya, bahasa XQuery dirancang agar setiap ekspresi XPath yang valid juga merupakan kueri XQuery yang valid.
yang memberikan output:
Sistem yang berbeda mungkin menampilkan output ini dengan cara yang berbeda. Secara teknis, hasil kueri ini adalah urutan dua simpul elemen dalam representasi pohon dari dokumen XML sumber, dan ada banyak cara yang mungkin dipilih sistem untuk menampilkan urutan seperti itu di layar. Stylus Studio memberi Anda pilihan tampilan teks dan tampilan hierarki: Anda menggunakan tombol di sebelah jendela Pratinjau untuk beralih dari satu ke yang lain.
Contoh ini menggunakan fungsi lain — end-with() — yang baru di XPath 2.0. Kami menyebutnya di dalam predikat (ekspresi antara tanda kurung siku), yang mendefinisikan kondisi yang harus dipenuhi oleh node agar dapat dipilih. Ekspresi XPath ini memiliki dua bagian: jalur .//actors/actor yang menunjukkan elemen mana yang kita minati, dan predikat [berakhir-dengan(., ‘Lisa’)] yang menunjukkan pengujian yang harus dipenuhi oleh node. Predikat dievaluasi sekali untuk setiap elemen yang dipilih; dalam predikat, ekspresi “.” (titik) mengacu pada simpul yang sedang diuji predikatnya, yaitu aktor yang dipilih.
Tanda “/” di jalur informal berarti “turun satu tingkat”, sedangkan “//” berarti “turun berapa pun tingkatnya”. Jika jalur dimulai dengan “./” atau “.//” Anda dapat mengabaikan inisial “.” (ini mengasumsikan bahwa pemilihan dimulai dari atas pohon, yang selalu terjadi dalam contoh kita). Anda juga dapat menggunakan konstruksi seperti “/..” untuk naik satu tingkat, dan “/@id” untuk memilih atribut. Sekali lagi, ini semua akan akrab jika Anda sudah tahu XPath. XPath mampu melakukan beberapa pilihan yang cukup kuat, dan sebelum kita beralih ke XQuery yang tepat, mari kita lihat contoh yang lebih kompleks. Misalkan kita ingin mencari judul semua video yang menampilkan aktor bernama depan Lisa. Setiap video dalam file diwakili oleh elemen video seperti ini: Banyak orang menemukan bahwa pada tingkat kerumitan ini, sintaks XPath menjadi agak membingungkan. Faktanya, contoh ini hanya tentang memperluas XPath hingga batasnya. Untuk jenis kueri ini, dan untuk hal yang lebih rumit, sintaks XQuery menjadi miliknya sendiri. Tetapi perlu diingat bahwa ada banyak hal sederhana yang dapat Anda lakukan dengan XPath saja, dan bahwa setiap ekspresi XPath yang valid juga valid di XQuery. Perhatikan bahwa Stylus Studio juga menyediakan penganalisis XPath bawaan untuk mengedit dan menguji ekspresi XPath yang kompleks secara visual, dan mendukung versi 1.0 dan 2.0.
![]()
![]()
![]()
![]()
![]()
Oracle Exec Lobi Untuk ‘Zorba’ Open-Source XQuery Engine
zorba-xquery – Bamford, arsitek utama untuk teknologi Oracle Server dan kadang-kadang dikenal sebagai bapak Real Application Clusters (RAC), mengatakan apa yang dibutuhkan dunia adalah mesin XQuery yang bebas dan terbuka. Untuk itu, dia telah meluncurkan FLWOR Foundation, dengan FLWOR berarti “Untuk-Biarkan-Di Mana-Pesanan-Kembali.”XQuery adalah standar yang diusulkan untuk query dan berinteraksi dengan data yang disimpan dalam bentuk XML. XML, atau Extensible Markup Language, telah menjadi lingua franca untuk menyimpan data nonrelasional dalam database dan repositori lainnya.Berbicara pada konferensi XML 2006 di Boston pada hari Selasa, Bamford melobi kerumunan untuk dukungan. Piagam Yayasan FLWOR adalah untuk membangun mesin gratis, berdasarkan C++, yang “akan berjalan pada apa pun dengan CPU dan RAM.” Dan itu harus “dapat dikonfigurasi hingga beberapa ratus K, dapat disematkan di browser, server, dan perangkat seluler,” katanya.
Oracle Exec Lobi Untuk ‘Zorba’ Open-Source XQuery Engine – Akan ada versi mesin, dijuluki Zorba, yang dihubungkan ke server Web Apache yang berjalan di database Berkeley gratis, sebuah kombo yang akan memasok hampir semua pengguna dengan “server XQuery/XML HTTP dan Layanan Web instan yang lengkap,” Bamford dikatakan.Keuntungan dari tumpukan database Zorba/Apache/Berkeley adalah karena kodenya sama, aplikasi benar-benar dapat diangkut lintas platform tanpa perubahan, menurut Bamford. Zorba juga akan mendukung banyak ekstensi bahasa, scripting dan windowing, tambahnya.Bamford juga memasang XML Application Platform (XAP), yang sekarang sedang dikembangkan oleh Oracle Special Projects Group, dan dia berjanji bahwa sebuah prototipe akan segera keluar.
Oracle Exec Lobi Untuk ‘Zorba’ Open-Source XQuery Engine
Sebuah platform untuk pengembangan aplikasi yang dihosting menggunakan infrastruktur XML, XAP akan menyertakan bagian-bagian seperti antarmuka pengguna, bahasa skrip berbasis XQuery, dan manajemen data XML sisi server. Bamford mengatakan itu juga akan mencakup model metadata aplikasi yang komprehensif dan aliran berbasis aturan.”Semuanya akan menjadi dokumen. Akan ada versi, tampilan, dan penyesuaian yang diizinkan,” katanya.Tujuan keseluruhannya adalah untuk mengaktifkan Web aplikasi daripada Web konten, kata Bamford. Meskipun Oracle mendukung upaya tersebut, ia menyatakan bahwa XAP yang telah selesai akan menjadi spesifikasi terbuka dan gratis. Bagian dari platform akan menjadi editor universal dan debugger untuk dokumen dan akan berjalan dalam mode klien/server di atas mesin Zorba.Konferensi XML 2006 minggu ini, disponsori oleh IDEAlliance, menandai peringatan 10 tahun karya pertama bahasa XML yang sekarang ada di mana-mana. Beberapa anggota kelompok kerja asli, termasuk Jon Bozak, berbicara di acara tersebut.
XQuery untuk analis atau arsitek sistem
W3C XML Query Working Group bekerja dengan W3C XML Schema Working Group dan W3C XSL Working Group untuk membuat satu set spesifikasi yang semuanya bekerja bersama. Gunakan XQuery untuk mengambil data dari beberapa database, dari file XML, dari dokumen Web jarak jauh, bahkan dari skrip CGI, dan untuk menghasilkan hasil XML yang dapat Anda proses dengan XSLT. Gunakan XQuery di bagian belakang server Web, atau untuk menghasilkan laporan eksekutif di seluruh Perusahaan.
Baca Juga : Berbagai Hal Yang Berkaitan Dengan Zorba Xquery
XQuery: memilih implementasi
Ada lebih dari 40 paket perangkat lunak berbeda yang mendukung XML Query dalam beberapa cara. Hal-hal yang harus dicari termasuk ketersediaan dukungan, platform, harga, kinerja, semua masalah biasa, tetapi Anda juga harus bertanya apakah perangkat lunak mendukung sintaks akhir dari Rekomendasi W3C atau mengimplementasikan draf sebelumnya. Fitur khusus Kueri XML lainnya adalah dukungan untuk file XML, untuk mengambil dokumen melalui HTTP, dan untuk menghubungkan ke sumber data relasional (atau lainnya): yaitu, apakah paket memenuhi janji Kueri XML untuk menyatukan akses ke berbagai bentuk informasi.
Spesifikasi W3C ditujukan pertama dan terutama pada programmer yang menulis implementasinya. Kami juga mencoba membuatnya mudah dibaca oleh orang-orang yang mencoba belajar bahasa tetapi diberi pilihan antara membuat standar yang tepat dan membuatnya mudah dibaca, kami harus membuatnya tepat. Jika Anda cukup teknis, Anda bisa mulai dengan membaca XML Spesifikasi kueri, dan dokumen Kasus Penggunaan XQuery memiliki beberapa contoh. Banyak orang lebih suka mencari buku atau tutorial.
Paket Uji XQuery
Test suite W3C ada untuk menunjukkan bahwa spesifikasi dapat diimplementasikan. Mereka sedang menguji spesifikasinya, bukan kodenya!
a. QT 3.0 Test suite adalah untuk orang yang mengimplementasikan XQuery 3, XPath 3, Functions and Operators 3 dan spesifikasi terkait.
b. Fasilitas Pembaruan XQuery 1.0 Test Suite
c. XQuery dan XPath Full Text 1.0 Test Suite (Bersama dengan XSLT WG)
d. XQuery 1.0 Test Suite yang jauh lebih lama tidak lagi digunakan.
Pengetikan Statis dan Semantik Formal
XPath 2 memiliki nilai yang diketik; yaitu, bahasa mengaitkan tipe nilai dengan setiap ekspresi, variabel, atau fungsi. Kumpulan tipe yang mungkin adalah yang didefinisikan oleh Skema XML W3C, ditambah dengan tipe yang ditentukan pengguna yang berasal dari tipe Skema dasar tersebut menggunakan skema eksternal. Cara sistem XPath atau XQuery memperoleh dan memeriksa jenis ekspresi didefinisikan secara formal, menggunakan notasi matematika, dalam Rekomendasi Semantik Formal XQuery 1.0 dan XPath 2.0. Perhatikan bahwa dukungan Skema W3C eksternal dan pengetikan statis adalah fitur opsional , jadi tidak semua implementasi mendukungnya.
Pernyataan Kesesuaian
Anda akan sering melihat hal-hal dalam spesifikasi yang ditandai sebagai implementasi yang ditentukan. Anda harus mendokumentasikan apa yang dilakukan implementasi Anda untuk masing-masing ini.Ada beberapa buku yang terdaftar; ada juga orang yang menawarkan pelatihan dan tutorial. Jika ada sesuatu yang menurut Anda sangat membantu, beri tahu kami. Ada juga beberapa milis yang dikhususkan untuk XML dan XML Query. Anda harus melihat arsip setiap daftar sebelum memposting; Anda juga harus berlangganan ke daftar sebelum Anda dapat memposting ke dalam banyak kasus. Ini adalah milis publik W3C pada bahasa query, termasuk (namun tidak terbatas pada) diskusi pada proyek XML Query. Jangan gunakan ini untuk mengirim komentar tentang spesifikasi, seperti ralat atau permintaan fitur; lihat bagian Status di setiap spesifikasi untuk petunjuk tentang cara mengirim komentar ke Kelompok Kerja. Milis yang dihosting di x-query.com, terutama untuk membahas XQuery. Mungkin daftar yang paling dikenal luas untuk membahas XML.
![]()
![]()
![]()
![]()
![]()

Berbagai Hal Yang Berkaitan Dengan Zorba Xquery
Berbagai Hal Yang Berkaitan Dengan Zorba Xquery – Pengantar Tentang Xquery. Xquery dapat digambarkan sebagai bahasa query XML (Extensible query language). Seperti namanya, XQuery adalah bahasa pemrograman kueri dan fungsional untuk bermain dengan data atau mengeluarkan data dari dokumen XML. Ini dikembangkan oleh W3C (World wide web consortium) untuk menarik data melalui web di seluruh dunia yang tersebar luas. Versi terbaru adalah versi 3.1 yang dirilis pada Maret 2017 setelah rilis sebelumnya pada tahun 2014. XPath adalah subset dari XQuery yang juga digunakan untuk mengekstrak data, tetapi sintaksnya berbeda dari XQuery. Ini bekerja sesuai dengan kueri SQL. Jadi, strukturnya dapat dengan mudah dipahami oleh pengembang SQL.
Berbagai Hal Yang Berkaitan Dengan Zorba Xquery
– Mengapa kita Membutuhkan XQuery?
Zorba-xquery – Penggunaan XQuery dapat dipahami dengan baik oleh pernyataan yang disebutkan di bawah ini yang diterbitkan di bawah W3C oleh J.Robie ketika XQuery diperkenalkan. “Misi dari proyek XML Query adalah untuk menyediakan fasilitas query yang fleksibel untuk mengekstrak data dari dokumen nyata dan virtual di World Wide Web, oleh karena itu akhirnya menyediakan interaksi yang dibutuhkan antara dunia Web dan dunia database. Pada akhirnya, kumpulan file XML akan diakses seperti database”.
Penggunaan utama XQuery adalah untuk mengekstrak data dari database XML. Itu juga mampu mengekstraksi data dari database relasional yang menyimpan data XML. XML mengikuti struktur hierarki yang berisi node di dalam node. Node ini ditangani oleh bahasa query XML. Ini juga digunakan untuk mengubah data dengan cepat. Itu berarti kami dapat memperbarui data saat transmisi itu sendiri. Fungsionalitas ini, ketika ditambahkan dengan bahasa kueri, memberikan kekuatan yang cukup untuk XQuery untuk menangani sebagian besar data XML melalui web.
– Bagaimana XQuery Bekerja?
Kita perlu memiliki prosesor yang membantu kita dalam merender penggunaan XQuery. Kita dapat menggunakan Saxon-HE (banyak digunakan). Karena ini adalah perangkat lunak sumber terbuka, kita dapat mengunduhnya dari internet bersama dengan buku panduan untuk instalasi. Kita perlu mengatur classpath seperti yang kita lakukan untuk instalasi JAVA. Ini mendukung versi terbaru XPath, XQuery, dan XSLT (Extensible Stylesheet Language Transformations). Kita dapat memiliki database untuk query atau memiliki file XML untuk mengekstrak data dari.
Ia bekerja di sekitar konsep FLWOR. FLWOR adalah singkatan dari From, let, where, order by, result. 5 kata ini membentuk keseluruhan kueri. Kita dapat menulis secara sederhana ke logika kompleks menggunakan 5 kata kunci ini di XQuery. Kami memilih sumber data dari kata kunci “dari”. “Let” digunakan untuk mendeklarasikan dan menginisialisasi variabel yang akan digunakan saat kita membuat loop kontrol. “Order by” digunakan untuk mengatur data dalam urutan menaik atau menurun. “Where” digunakan untuk membatasi ruang lingkup dengan mendeklarasikan kondisi spesifik dari penarikan data. Ini berfungsi seperti kata kunci “dari” dalam SQL. “Kembali” akan menandai akhir kueri dan kata kunci ini akan mentransfer kontrol keluar dari kueri bersama dengan output.
Jika kita memiliki file data XML bernama “test.xml”, kita dapat membuat kueri dan menyimpannya dalam file terpisah dengan ekspresi yang relevan. Di sini kita dapat menyimpan kueri kita dalam file bernama “testquery.xqy”. Kami kemudian membutuhkan program driver di JAVA yang akan membuat koneksi dengan database menggunakan objek koneksi. Setelah koneksi dipertahankan, dan kumpulan hasil diinisialisasi. Kami dapat menjalankan kueri ini dengan memasukkan file kueri dalam program driver JAVA. Dalam hal ini, kita dapat memiliki program JAVA bernama “querydriver.java”.
XQuery harus dicakup di bawah tag <html> agar berfungsi. Di sini variabel seperti “buah” dan “warna” dilambangkan dengan simbol dolar “$” di awal. Pernyataan kembali berada di akhir nilai keluaran.
Fitur dan Keunggulan XQuery
Berikut ini adalah berbagai fitur dan keunggulan XQuery.
Fitur
Beberapa fitur penting dari bahasa XQuery ditunjukkan di bawah ini:
XQuery adalah bahasa pemrograman fungsional yang tidak hanya mendukung bahasa kueri tetapi juga menawarkan untuk melakukan perubahan data sehingga mempromosikan situs web dinamis.
XQuery memiliki sintaks sederhana pada baris bahasa SQL. Sangat mudah untuk memahami dan kuat pada saat yang sama.
XQuery bekerja untuk menggali ke dalam struktur hirarkis sampai menemukan data. Hal yang sama dapat dilihat ketika kita menavigasi melalui path di file manager windows. XPath yang digunakan untuk menarik data berdasarkan jalur file adalah komponen XQuery.
Ini adalah bahasa universal. Dengan demikian, itu diterima di seluruh dunia dengan standar tertentu yang harus diikuti seperti yang didefinisikan oleh W3C. Kesederhanaan dan sintaksisnya mendorong pembuat kode untuk menerapkannya dalam proyek.
Keuntungan
Beberapa keuntungan tercantum di bawah ini:
XQuery dapat digunakan untuk mengekstrak data dari semua jenis struktur seperti struktur data hierarkis, tabular, atau grafis.
Ini dapat digunakan untuk menarik data langsung dari situs web. Ini mengurangi banyak pekerjaan dan menghemat waktu.
Demikian pula, XQuery dapat digunakan untuk membangun situs web. Mengurangi jumlah upaya yang kami lakukan untuk membangun situs web.
Ia bekerja secara efisien dengan database relasional.
Seiring dengan kueri, ini dapat digunakan untuk mengubah data saat mentransmisikannya. Ini berguna untuk penanganan data dinamis. Karena fungsi ini, kita dapat XQuery sebagai bahasa pemrograman fungsional juga.
Ini dapat digunakan dengan database berorientasi objek serta mengurangi ketidakcocokan impedansi.
Kesimpulan
XQuery adalah salah satu bahasa universal yang banyak digunakan yang mampu menampilkan, mengambil, mengubah data melalui halaman web dinamis. Ini dikembangkan untuk menantang bahasa kompleks seperti C++, JAVA, dll. Kita dapat memiliki logika yang ditulis dalam XML dan hanya menggunakan file JAVA untuk membuat dan memelihara koneksi dengan database.
– Artikel yang Direkomendasikan
Ini adalah panduan untuk XQuery. Di sini kita membahas Pendahuluan dan mengapa kita membutuhkan XQuery beserta fungsi, fitur, dan kelebihannya. Anda juga dapat melihat artikel berikut untuk mempelajari lebih lanjut
![]()
![]()
![]()
![]()
![]()